让 AI 真正拥有“长时记忆”的开端
为什么谷歌要重新设计序列模型的“记忆系统”?
在大模型时代,模型的“记忆”问题正变得越来越重要。
我们已经能让模型写长文、读文档,但一个根本性的限制始终存在:模型无法在极长序列中保持稳定、细致、可深入推理的长期记忆能力。
Transformer 带来了强大的注意力机制,但随着序列长度增长,计算成本会以平方级上升。
而近年来兴起的高效 RNN 与状态空间模型(SSM),虽然推理速度快、可扩展性强,却需要依赖一个固定大小的状态向量来“压缩过去”,难以承载海量信息。
在两篇最新论文中,谷歌提出了两个概念:
-
• Titans:一种使用深度神经网络作为长期记忆的全新架构; -
• MIRAS:一个从理论上重新定义序列模型“记忆行为”的框架。
两者共同指向一个核心命题:
让 AI 在推理时能够主动、实时地更新自身记忆,不依赖离线训练,不依赖固定压缩状态,从而真正拥有可持续的长期知识。
一、长序列瓶颈:Transformer 不擅长长期记忆
Transformer 的核心在于 Attention,它让模型能自由访问历史信息。但注意力计算的成本与序列长度 L 的平方(O(L²)) 成正比,这让模型很难处理数十万、数百万级别的上下文。
为解决这个问题,人们尝试:
-
• 高效线性 RNN -
• SSM(如 Mamba-2 等)
它们的共同特点是:
-
• O(L) 的推理成本,足够快; -
• 但只能用一个固定大小的向量或矩阵来保存所有历史信息。
长期来看,这种“小容器记忆”必然面临瓶颈:
序列越来越长,而记忆大小不变。
信息被迫压缩,细节必然丢失。
二、Titans:将“记忆”从向量升级为“神经网络”
Titans 引入的关键创新,是把长期记忆从传统 RNN 中一个固定的 hidden state 彻底升级为一个深度多层感知机(MLP)本身。
也就是说:
Titans 的记忆不是一个“记忆向量”,
而是一整个可更新的 深度网络参数集。
这种设计带来几个重要变化:
1. 记忆容量随网络深度提升,远超传统结构
固定向量容量有限,而深度网络可以表达复杂结构关系,更适合总结长序列信息。
2. 模型可以实时写入新的长期知识
Titans 的长期记忆模块可以在推理过程中更新,而不需要重新训练。
3. 短期与长期记忆分工明确
-
• Attention 负责处理短期、精确的局部关系; -
• 长期记忆网络负责总结、抽象、跨段落逻辑。
这让 Titans 的记忆系统更接近人类的“工作记忆 + 长期记忆”结构。
三、如何判断“哪些信息值得写入长期记忆”?
人类不会记住所有细节,我们记住的往往是违背预期的事情。Titans 模型借鉴了心理学中这一现象,引入:
惊讶度(Surprise Metric)
其数学形式来源于模型内部的梯度变化:
-
• 低惊讶:模型已能预测到的内容 → 不必写入长期记忆 -
• 高惊讶:突破预期、重要或异常的信息 → 优先写入
Titans 会在推理过程中监控惊讶度,从而决定:
-
• 何时更新长期记忆 -
• 记什么 -
• 忽略什么
为了避免记忆混乱,Titans 还加入:
1. 动量机制(Momentum)
不仅看当前惊讶值,还会参考最近一段时间的连续惊讶变化,让模型捕捉成片的新信息,而不是碎片化的点。
2. 遗忘机制(Forgetting)
通过一种自适应的 weight decay,对长期不再相关的内容自然衰减,使记忆保持容量健康、结构清晰。
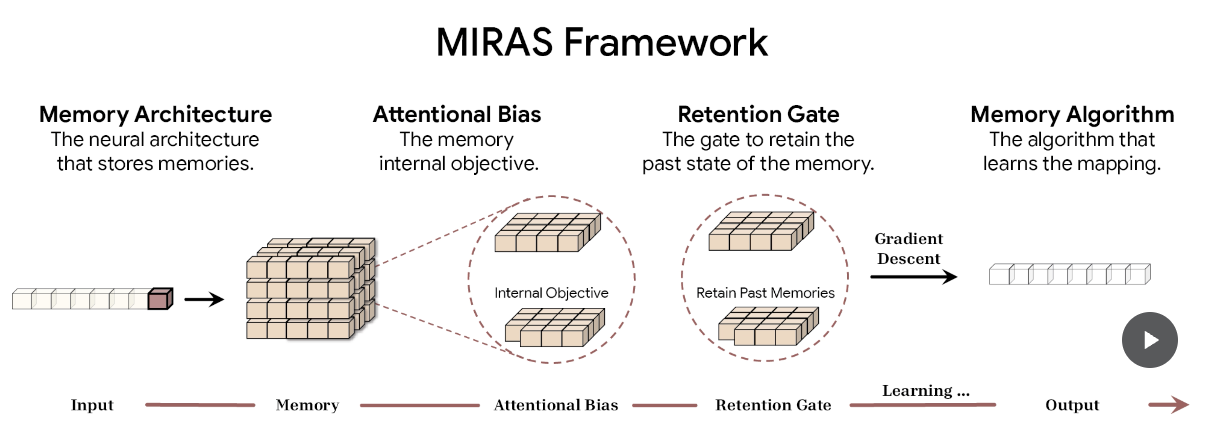
四、MIRAS:重新定义“序列模型 = 关联记忆系统”
MIRAS 是 Titans 背后的理论基础,它提出一个新的视角:
所有序列模型 —— 无论 Transformer、RNN、SSM —— 本质上都是试图学习一种“可查询的关联记忆”。
在 MIRAS 中,一个序列模型由四个维度决定:
-
1. 记忆结构:是向量、矩阵,还是深度网络? -
2. 学习偏置(Attentional Bias):模型优化哪些目标? -
3. 保留门(Retention Gate):如何平衡新旧记忆? -
4. 记忆算法(Memory Algorithm):采用何种优化策略更新记忆? -
MIRAS 的优势在于统一解释了不同架构之间的差异
例如:
-
• Transformer 的注意力行为可被视为特定的 bias + regularization -
• RNN 的遗忘门是 retention gate 的一种实现形式 -
• Titans 的深度记忆是一种更高维的 memory architecture
这让我们可以用同一套语言来描述不同模型的记忆行为。
五、突破 MSE:非欧式几何目标的探索空间
现有序列模型几乎全部依赖:
-
• MSE(均方误差) -
• dot-product(点积相似度)
它们属于欧式几何范畴,简单但容易受异常点影响。
基于 MIRAS,谷歌提出三种“不依赖注意力”的新模型:
-
• YAAD:采用 Huber Loss,对噪声更鲁棒 -
• MONETA:引入严格的广义范数,提高记忆稳定性 -
• MEMORA:把记忆约束为概率分布,保证更新过程可控
它们代表了未来研究方向:
更丰富的目标函数,更灵活的记忆几何结构。
六、实验结果:Titans 在长序列任务上全面领先
谷歌在多项基准任务上验证了 Titans 与 MIRAS 变体:
1. 语言建模(C4、WikiText)
-
• 长期记忆越深,模型困惑度越低 -
• 大幅优于 Mamba-2、Gated DeltaNet 等高效模型
2. 零样本推理(HellaSwag、PIQA)
Titans 与 MIRAS 系列表现均优于同尺度的 baseline。
3. 极长上下文(BABILong Benchmark)
这是最关键的部分。
在需要处理 200 万 token 级别上下文的极端任务中:
Titans 甚至超过了 GPT-4 级别的大模型(参数量远大于 Titans)。
同时保持线性推理速度,性能随序列长度持续稳定。
七、为什么这项研究意义重大?
Titans 与 MIRAS 的提出,说明:
-
1. 大模型未来的方向不是“只变大”,而是“变得更能记忆”。 -
2. 序列模型的核心竞争力正在从注意力扩展到“高级记忆结构设计”。 -
3. 推理阶段在线更新记忆,将成为下一代 AI 能力的关键基础设施。
更远的意义在于:
AI 将不再是“每次都从零开始预测”的系统,
而是一个能够随着使用而不断调整内部知识的学习体。
这将改变搜索、对话系统、企业知识库、科学计算等广泛场景的能力边界。
结语
Titans 提供了一个全新的记忆架构,MIRAS 提供了统一的理论框架。
两者共同推动了序列模型从“短暂记忆机器”向“具有持续学习能力的知识系统”演化。
从高效 RNN 到 Transformer,从注意力机制到深度记忆网络,
这次谷歌的工作可能标志着大模型迈向 “长时知识时代” 的一个关键节点。
如果觉得内容不错,欢迎你点一下「在看」,或是将文章分享给其他有需要的人^^
相关好文推荐:
0条留言