D4RT:教会 AI 以四个维度看世界 | DeepMind
作者:Google DeepMind | 日期:2026年1月22日
介绍 D4RT,一个用于跨越空间与时间的 4D 场景重建与跟踪的统一 AI 模型
每当我们观察世界时,我们都会完成一项非凡的记忆与预测壮举。我们不仅能看到并理解某一时刻事物的状态,也能理解它们在上一刻的样子,以及它们在下一刻将会如何变化。我们的心智模型维持着一个对现实的持续性表征,而我们正是借助这一模型,对过去、现在与未来之间的因果关系作出直觉性的判断。
为了帮助机器更像我们一样看世界,我们可以为它们配备摄像头,但这只解决了输入的问题。要理解这些输入,计算机还必须解决一个复杂的逆问题:从视频——也就是一系列平面的二维投影——中,恢复或理解一个正在运动的、丰富的三维体积世界。
今天,我们介绍 D4RT(Dynamic 4D Reconstruction and Tracking,动态四维重建与跟踪),这是一个将动态场景重建统一到单一、高效框架中的全新 AI 模型,使我们更接近人工智能的下一个前沿:对动态现实的全面感知。
第四维度的挑战
为了理解由二维视频捕捉到的动态场景,AI 模型必须在三维空间和第四维——时间——中,跟踪每一个物体的每一个像素。此外,它还必须将物体的运动与相机的运动区分开来,即使物体相互遮挡,或者完全离开画面,也要保持一个连贯的表征。传统上,从二维视频中捕捉这种程度的几何与运动信息,往往需要计算代价高昂的流程,或者拼接多种专用 AI 模型——有的用于深度,有的用于运动,有的用于相机姿态——这会导致 AI 重建过程缓慢且割裂。
D4RT 简化的架构与新颖的查询机制,使其站在 4D 重建领域的前沿,同时在效率上比以往方法最高可提升 300 倍——快到足以支持机器人、增强现实等实时应用。
D4RT 的工作原理:一种基于查询的方法
D4RT 采用统一的编码器–解码器 Transformer 架构。编码器首先将输入视频处理为对场景几何和运动的压缩表示。与使用多个模块分别处理不同任务的旧系统不同,D4RT 通过一种灵活的查询机制,只计算它真正需要的信息,这种机制围绕着一个单一且基础的问题展开:
“视频中的某个像素,在任意时间点、从选定的相机视角来看,它在三维空间中的位置在哪里?”
在我们先前工作的基础之上,一个轻量级的解码器对这一表示进行查询,以回答该问题的具体实例。由于这些查询彼此独立,它们可以在现代 AI 硬件上并行处理。这使得 D4RT 极其快速且具备良好的可扩展性,无论是只跟踪少量点,还是重建整个场景,都同样高效。
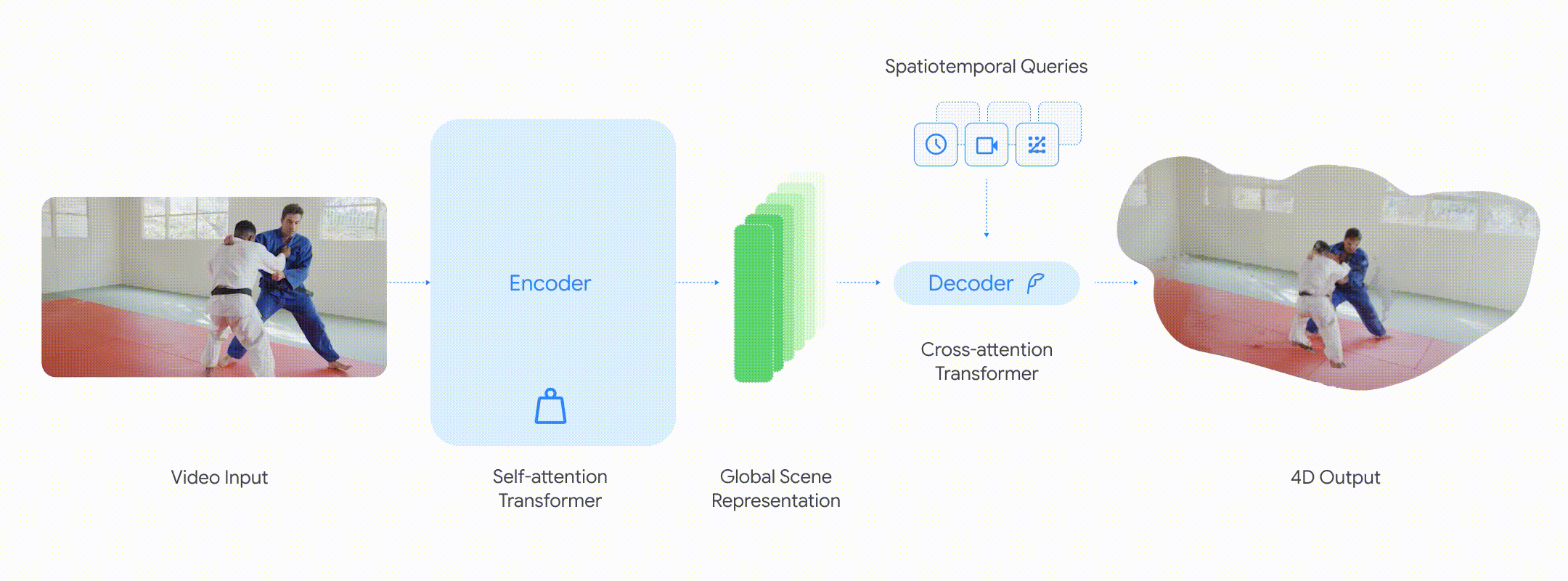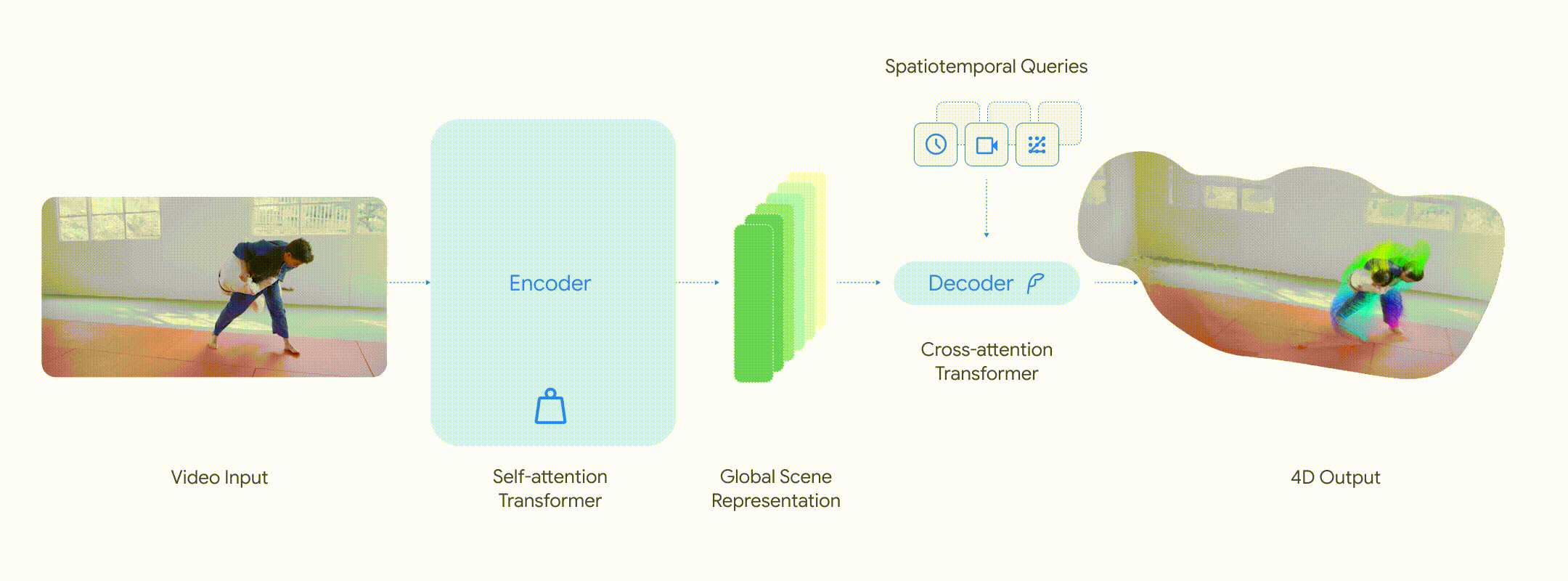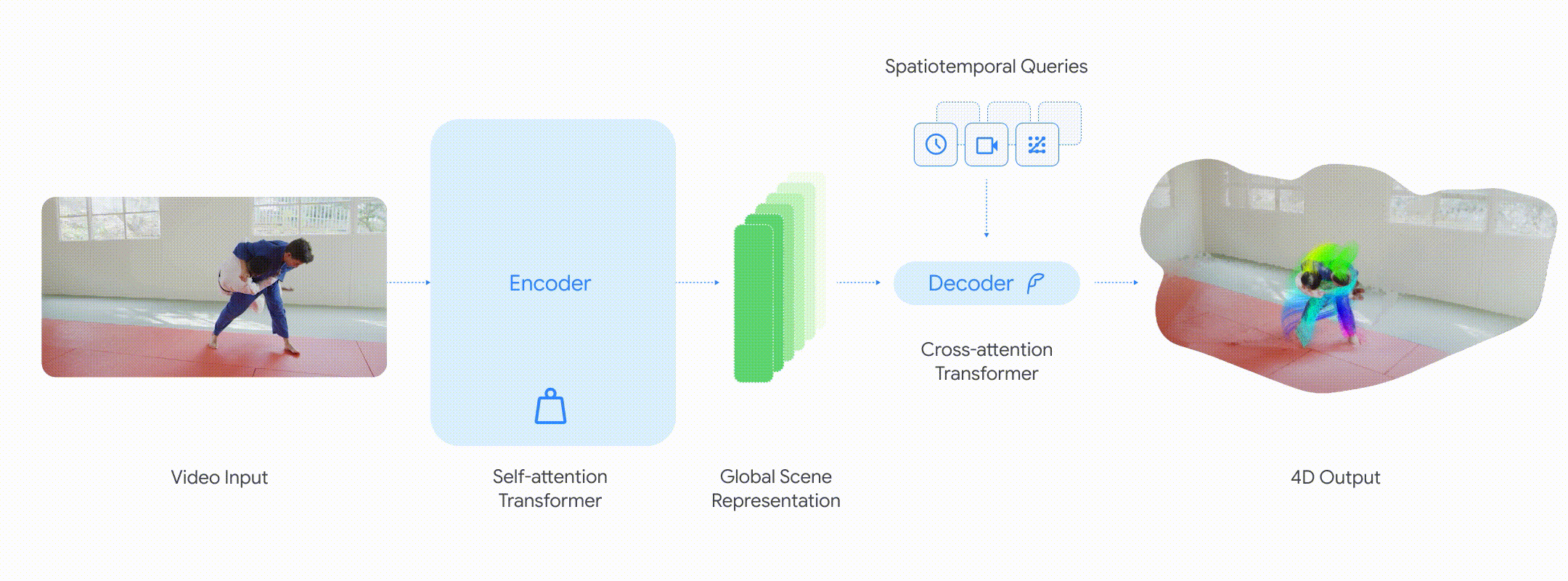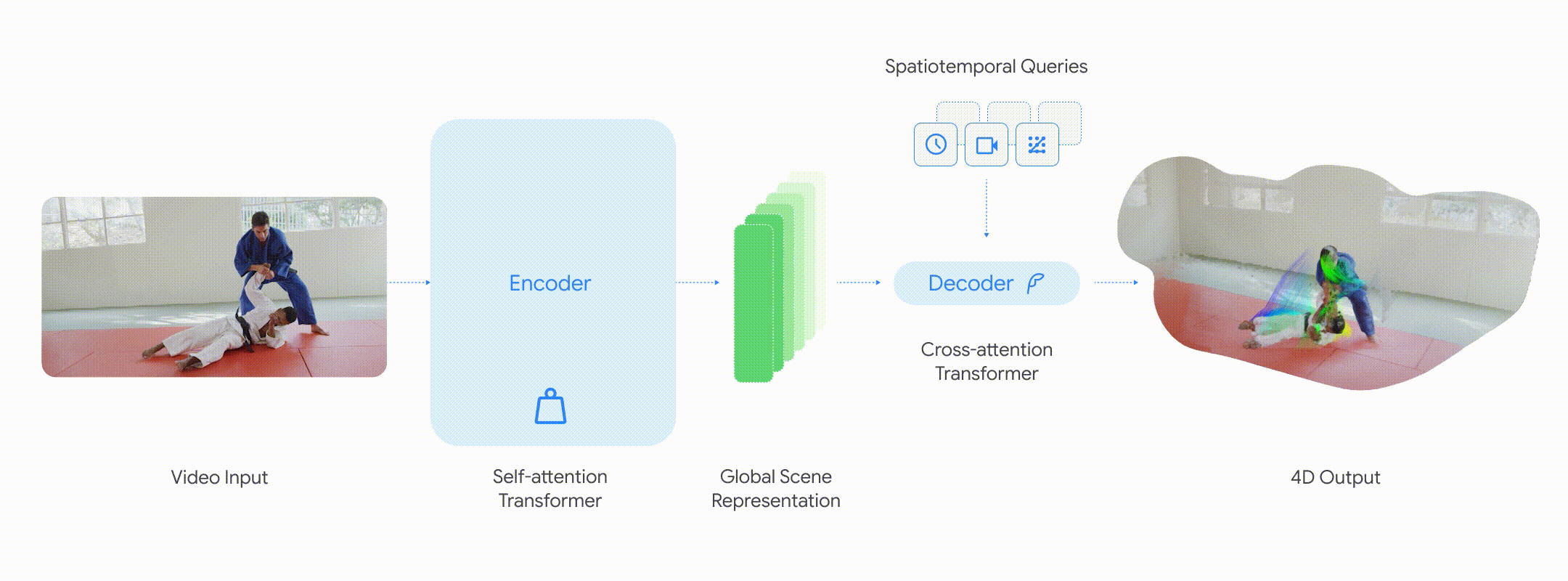
能力:快速、准确的 4D 理解
借助这种灵活的表述方式,模型现在可以解决多种 4D 任务,包括:
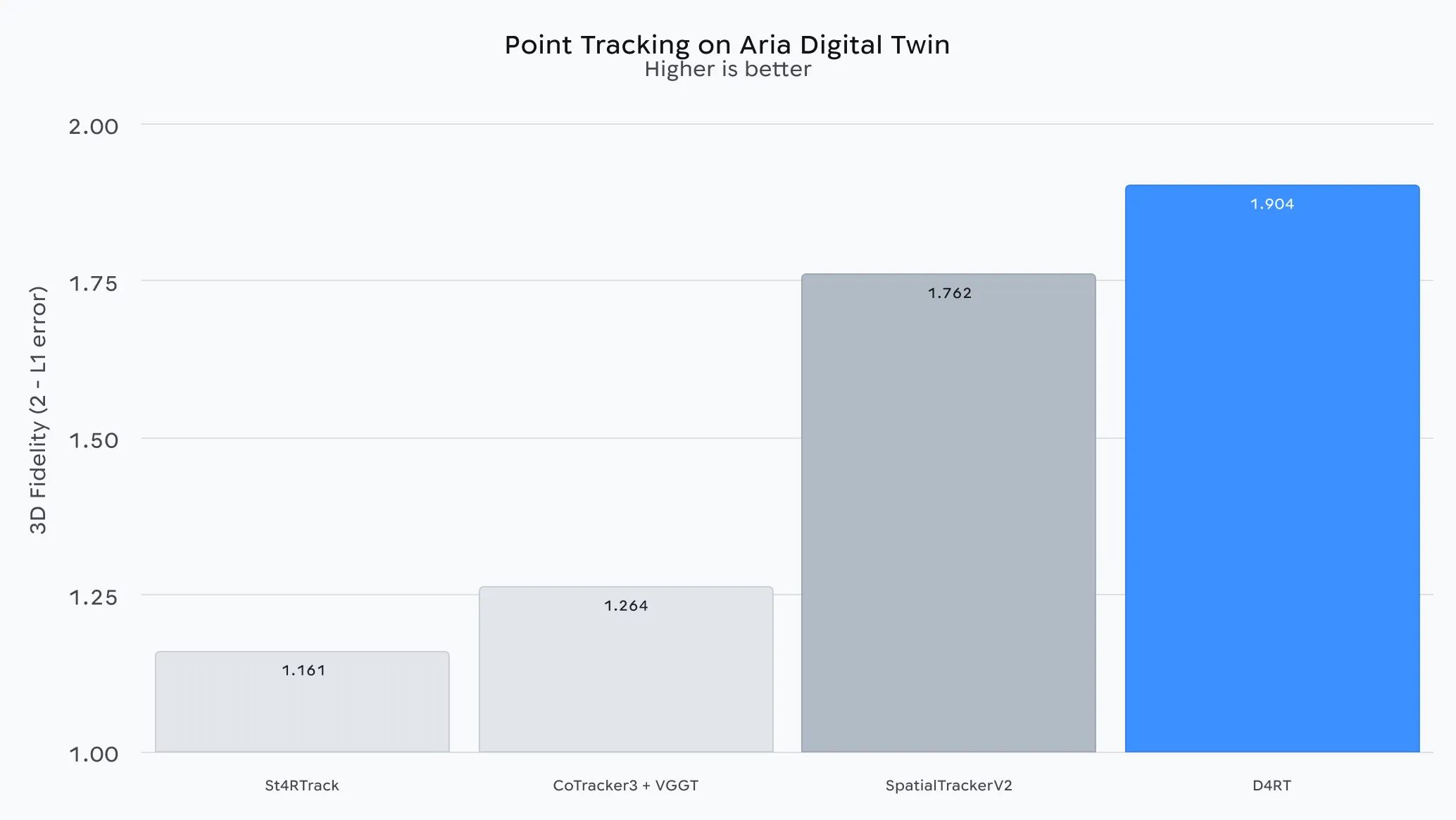
• 点跟踪:通过查询某个像素在不同时间步上的位置,D4RT 可以预测其三维轨迹。重要的是,即使该物体在视频的其他帧中并不可见,模型也能作出预测。
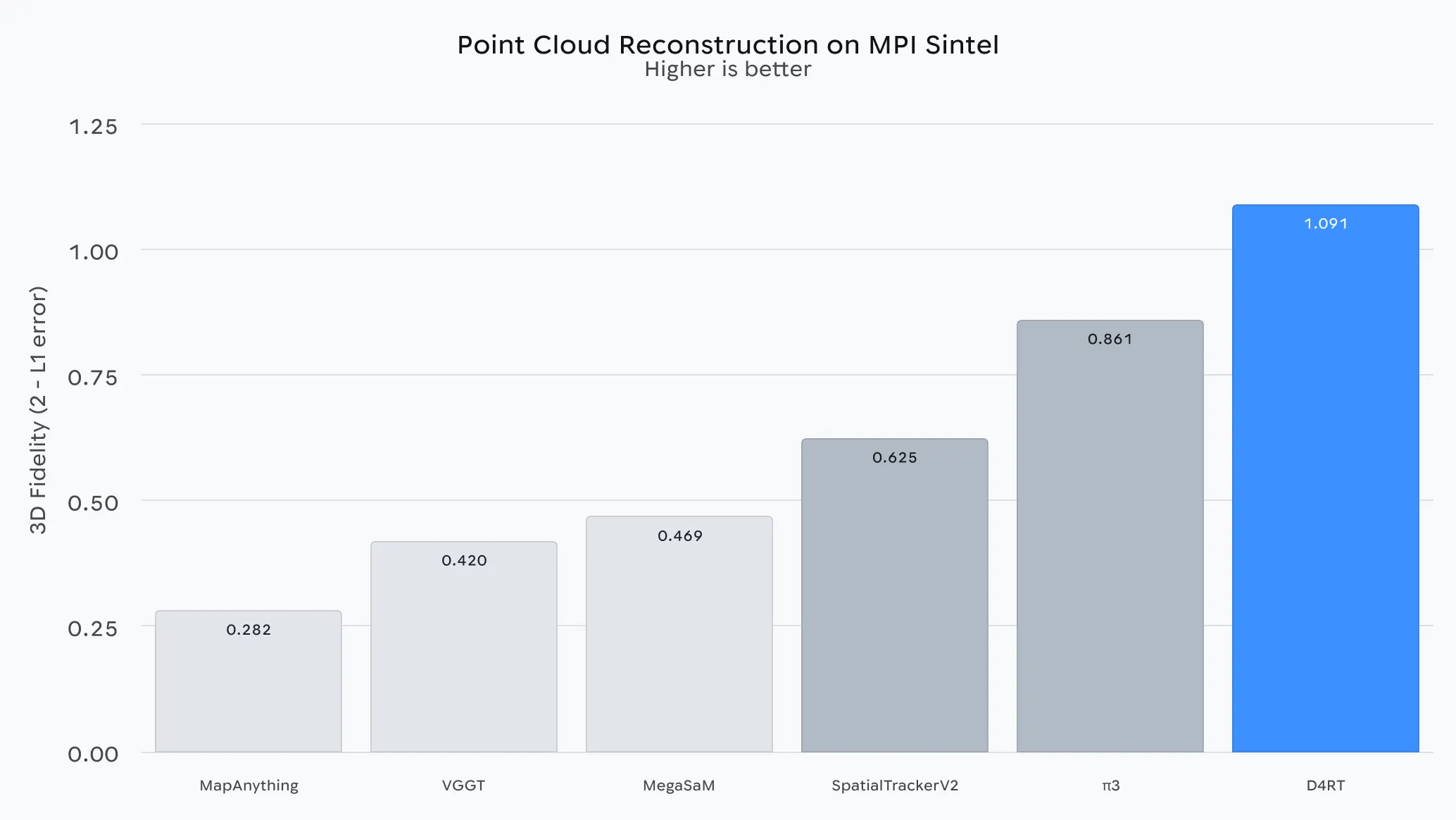
• 点云重建:通过冻结时间和相机视角,D4RT 可以直接生成场景的完整三维结构,从而消除诸如单独的相机估计或逐视频迭代优化等额外步骤。
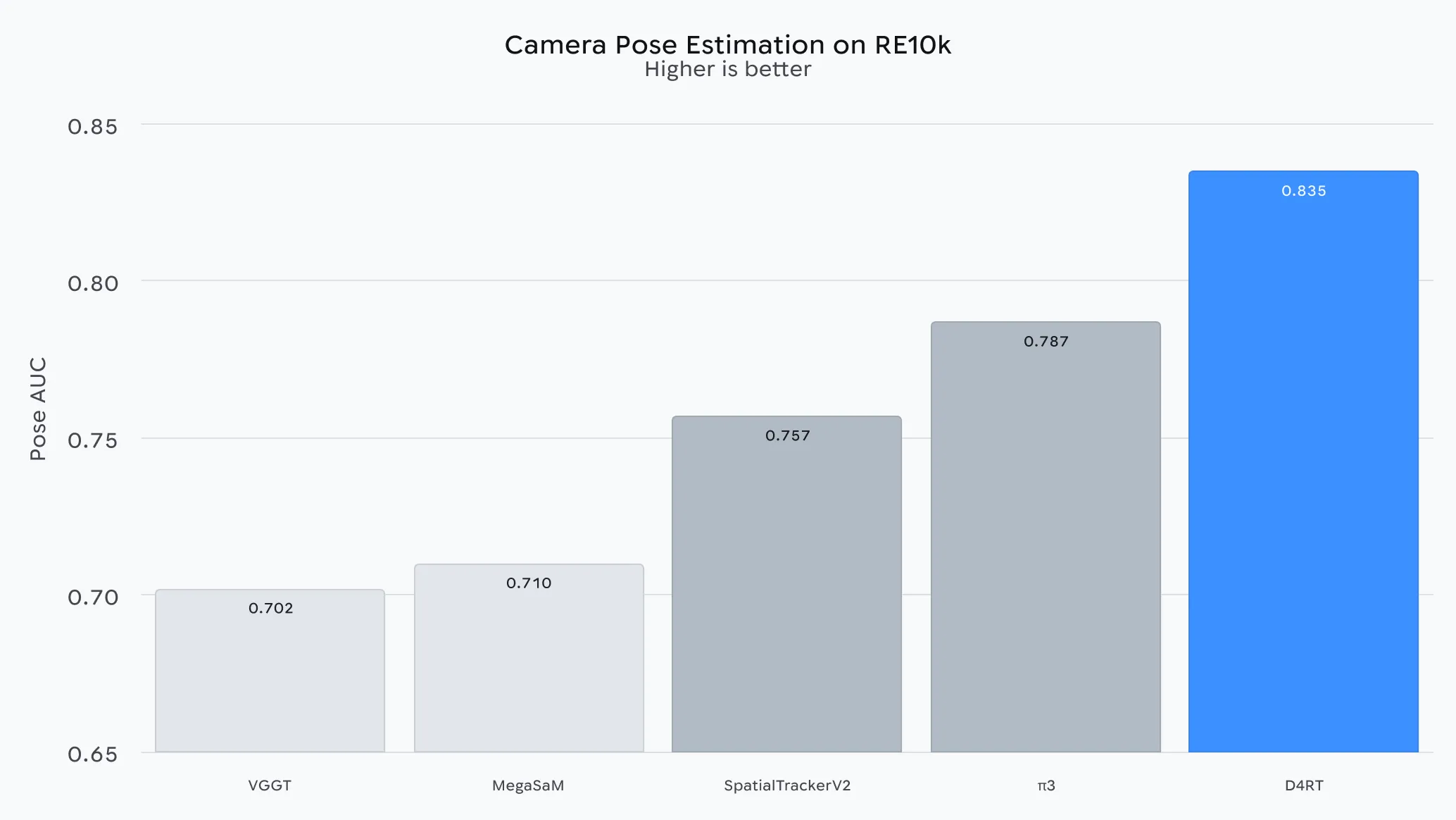
• 相机姿态估计:通过从不同视角生成并对齐同一时刻的三维快照,D4RT 可以轻松恢复相机的运动轨迹。

正如底层技术报告中所详述的那样,D4RT 在广泛的 4D 重建任务上都优于以往方法。定性对比显示,其他方法在处理动态物体时往往表现不佳——常常会重复重建同一物体,或者完全无法重建——而 D4RT 则能保持对运动世界的稳定、连续理解。
至关重要的是,D4RT 的精度并未以牺牲效率为代价。在测试中,它比此前的最先进方法快了 18 到 300 倍。例如,D4RT 在单个 TPU 芯片上处理一段一分钟的视频大约只需五秒钟,而此前的最先进方法完成同样的任务可能需要长达十分钟——提升幅度达到 120 倍。
下游应用
D4RT 证明了在 4D 重建中,我们不必在精度和效率之间做出取舍。其灵活的、基于查询的系统能够实时捕捉我们所处的动态世界,为下一代空间计算铺平道路。这包括:
• 机器人:机器人需要在充满移动人员和物体的动态环境中进行导航。D4RT 可以提供安全导航和灵巧操作所需的空间感知能力。
• 增强现实(AR):为了将数字物体叠加到现实世界中,AR 眼镜需要对场景几何结构具备即时、低延迟的理解。D4RT 的高效性有助于使端侧部署成为切实可行的现实。
• 世界模型:通过有效地区分相机运动、物体运动和静态几何结构,D4RT 让我们更接近拥有真正物理现实“世界模型”的 AI——这是通往通用人工智能道路上的一个必要步骤。
我们将继续探索该模型的能力,并挖掘其在机器人、增强现实及其他领域中的应用潜力。
阅读我们的技术报告:https://arxiv.org/abs/2512.08924
访问我们的项目网站:https://d4rt-paper.github.io/
https://deepmind.google/blog/d4rt-teaching-ai-to-see-the-world-in-four-dimensions

0条留言