关于 Claude 如何实现 92% 缓存命中率的一个案例研究 | Akshay
作者:Akshay | 日期:2026年3月9日
每当一个 AI agent 执行一步,它都在缴一种税。
它会从头再读一遍所有内容。
系统指令、工具定义、它三轮前已经加载过的项目上下文。全部都要重读。每一轮都是这样。
这就是上下文税。对于长时间运行的 agent 工作流来说,它往往是你整个 AI 基础设施里最贵的一项成本。
算一下就知道了:一个 20,000 token 的 system prompt,运行 50 轮,就意味着有 100 万 token 的重复计算按原价计费,却没有产生任何新增价值。
解决办法是 prompt caching。但如果你想把它用好,就需要理解底层到底发生了什么。
先区分哪些会变,哪些不会变
在你优化任何东西之前,必须先把 agent 的 prompt(上下文)结构想清楚。
你的 agent 发出的每一个请求,实际上都由两部分完全不同的内容组成:
-
• 静态前缀:包括系统指令、工具定义、项目上下文、行为规则。这些内容在同一次会话的每一轮里都是一样的。 -
• 动态尾部:包括用户消息、工具输出、终端观察结果。这些内容每次请求都不同,而且会随着对话推进不断增长。
这个区分非常关键。静态前缀是你在无意义地反复重算的昂贵部分;动态尾部才是唯一真正需要重新计算的部分。
Prompt caching 的工作方式,就是把静态前缀对应的数学状态保存下来,这样后续请求就可以完全跳过这一段的重复计算。你只需要为处理这段前缀付费一次。之后每一轮都直接从“内存”里读取。
为什么这能成立:Transformer 实际上在做什么
如果你想真正理解缓存为什么这么有效,就要先理解模型读取 prompt 时内部发生了什么。
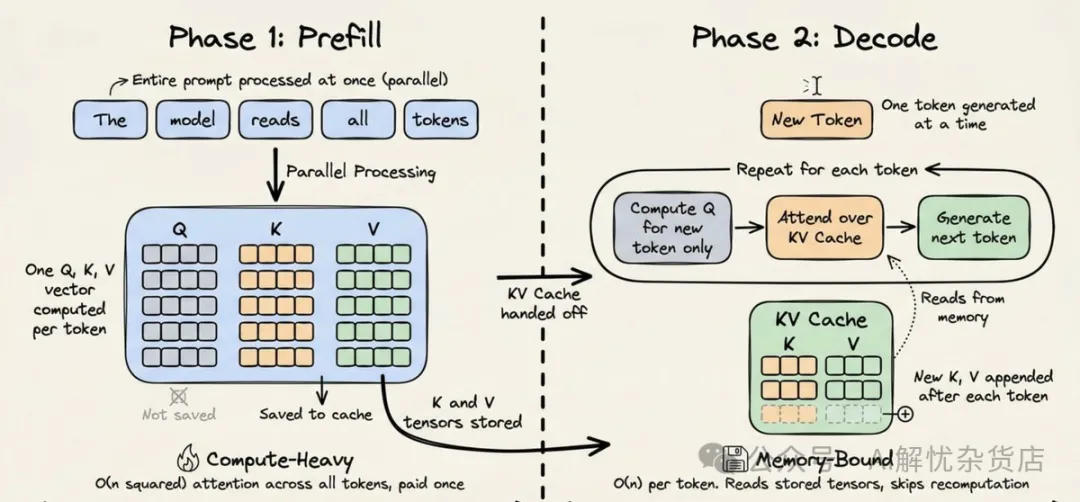
每一次 LLM 推理请求都有两个阶段:
阶段 1:Prefill
这一阶段里,模型会处理完整的输入 prompt。它是计算密集型的,也就是说它要对上下文中的每一个 token 执行大规模矩阵乘法。模型会读完整个输入,并构建出对它的内部表示。这一阶段既慢又贵。
阶段 2:Decode
这一阶段里,模型会一个 token 一个 token 地生成输出。它更多是内存带宽受限,而不是算力受限,因为模型大部分时间都在读取先前已经计算好的状态,而不是继续做重型计算。
在 prefill 阶段,transformer 会为每个 token 构造三类向量:Query、Key 和 Value。注意力机制依靠这些向量来判断一个 token 与序列中其他 token 的关系。
关键点在这里:Key 和 Value 向量只依赖于它之前出现过的 token。一旦它们针对某个前缀被计算出来,就不需要再改变。
下图直观地解释了我们刚刚讨论的内容:
如果没有缓存,这些 Key-Value tensor 会在一次请求结束后立即被丢弃。下一次请求会从头开始,再次为那 20,000 个 token 全量重算。
KV caching 的解决方案就是把这些 tensor 存起来。 基础设施会把它们保留在推理服务器上,并用输入文本的加密哈希来索引。当一个新请求带着同样的前缀进来时,哈希匹配成功,tensor 会被立即取回,模型就可以跳过这部分计算。
这样会把每个生成 token 的计算复杂度从 O(n²) 降到 O(n)。对于一个在 50 轮中反复复用的 20,000-token 前缀来说,这是非常巨大的优化。
经济账
理解计费结构,才能理解为什么这是一个影响架构决策的大问题。
Anthropic 在不同模型家族上的缓存定价大致如下:
有三个数字必须记住:
-
• 缓存读取的价格只有基础输入价格的 10%,也就是每个从缓存中读出的 token 都打了 9 折中的 9 折。 -
• 缓存写入的价格比基础输入价格高 25%,这是为了存储 KV tensor 支付的一点额外成本。 -
• 延长到 1 小时的缓存价格是基础价格的 2 倍。
只有当你的缓存命中率足够高时,这笔账才划算。接下来就看一个现实世界里最典型的例子。
Claude Code:一个 30 分钟会话的拆解
Claude Code 的核心目标只有一个:让缓存保持热状态。
为了具体理解这意味着什么,我们按时间线看一个典型的 30 分钟编码会话,并跟踪每一步究竟哪些内容在计费,哪些没有。
第 0 分钟:会话开始
Claude Code 会加载系统 prompt 和工具定义。它还会读取你项目根目录下的 CLAUDE.md 文件,用来描述代码库和约定。这部分负载通常会超过 20,000 token。
这是整场会话里最贵的时刻。因为每一个 token 都是新的。但这个成本你只付一次。
第 1 到 5 分钟:第一批命令
你输入第一条指令,比如 “look at the auth module and suggest improvements.”
Claude Code 会派出一个 Explore Subagent。它浏览代码库、打开文件、运行 grep 命令,建立对相关代码的理解。这些内容都会追加到动态尾部里。
那 20,000 token 的静态基础部分呢?已经在缓存里了。读取它们的价格是 3.00/MTok。你只需要为新的工具输出和你的新消息付费。
第 6 到 15 分钟:深入工作
Plan Subagent 会接收 Explore Subagent 的发现。它不会原封不动地传递全部原始结果,因为那会不必要地让动态尾部膨胀;Claude Code 会传递一个简洁摘要。这样后缀更可控,缓存也更高效。
规划器随后生成一个结构化的实施计划。你审核、批准,然后 Claude Code 开始改动代码。在这一循环中的每一轮,20,000-token 的前缀都是从缓存中读取。每一次命中都会刷新 TTL,让缓存继续保持热状态。
第 16 到 25 分钟:迭代
你提出调整要求。Claude Code 修改它的方案。更多工具调用,更多终端输出。动态尾部在增长,但它只代表这次会话中新增且独特的内容。
到这个阶段,这场会话已经总共处理了几十万 token。但那 20,000-token 的基础部分在每一轮里都直接从缓存读取。
第 28 分钟:运行 /cost
如果没有缓存,一次这样的会话很容易超过 200 万 token。按照 Sonnet 4.5 的价格,大概就是 6 美元。
而在高效率缓存下:
-
• 绝大多数 token 都会以 $0.30/MTok 的价格从缓存读取。 -
• 只有新的动态尾部 token 需要重新计算。
在实践里,你通常可以期待单次任务成本下降 80% 以上。再把这个数字乘上每天的所有用户、所有任务。
总结一下,以下是系统提示布局随着会话继续的样子:
一条会毁掉一切的规则
Prompt caching 最反直觉的地方在这里。
1 + 2 = 3。但 2 + 1 会变成一次缓存未命中。
基础设施会对 prompt 做哈希。这个哈希本质上是一个用于加密的标识符。只要顺序发生变化,哪怕只是两个元素位置互换,哈希都会改变。缓存就失效了。整个前缀都要重新按原价计算。
由此会推导出三条规则:
-
• 不要在会话中途增减工具。缓存的前缀里包括工具定义,工具一变,后面整段缓存价值都会消失。 -
• 不要在同一会话中途切换模型。缓存是模型专属的。中途换到更便宜的模型,意味着整个缓存都要重建。 -
• 不要通过修改前缀来改变状态。Claude Code 的做法是把提醒系统的 tag 加到下一条用户消息里。前缀本身不变。
这对你意味着什么
上面讲的是 Claude Code 如何处理缓存。如果你在构建自己的 agent,同样的规则也成立。
你的 prompt 结构应该这样设计:
-
• 最上面是系统指令和规则。中途不要改。 -
• 预先加载好你会需要的所有工具。不要中途增减。 -
• 再往后是检索得到的上下文和文档,这部分在会话期间保持静态。 -
• 最后才是对话历史和工具输出。
开启 auto-caching 之后,cache breakpoint 会随着对话推进自动向前移动。
Claude Code 自己负责管理缓存。Anthropic 刚刚在 API 里加入了 auto-caching,所以你也可以对自己的 agent 这样做。
在没有 auto-caching 的时候,你得自己记住 token 边界在哪里。边界划错了,就等于根本没有命中缓存。
当你为了上下文窗口上限而进行压缩时,要使用 cache-safe forking。保持相同的 system prompt、工具和对话,只把压缩动作作为一条新消息追加进去。
这样一次 compaction 调用看起来和上一轮几乎一样。缓存前缀仍然可以复用。唯一按“新内容”计费的,只是这条压缩指令。
如果你想判断一个 API 是否真的在正常利用缓存,请盯住每次响应里的这三个字段:
-
• cache_creation_input_tokens:写入缓存的 token 数 -
• cache_read_input_tokens:从缓存中读取的 token 数 -
• input_tokens:按常规方式处理的 token 数
你的缓存效率分数,就是读取 token 数相对于创建 token 数的比例。像盯 uptime 一样盯住它。
核心结论
Prompt caching 不是一个你打开就完事的功能。它是一种需要围绕它来构建的架构纪律。
Claude Code 是目前最好的大规模实践案例之一。
92% 的缓存命中率,81% 的成本下降。
如果你在做 agent,这就是一份蓝图。你无法忽略这笔税;它一定存在。真正重要的,只是你究竟是在为它付费,还是在把它消除掉。
https://x.com/akshay_pachaar/status/2031021906254766128
如果觉得内容不错,欢迎你点一下「在看」,或是将文章分享给其他有需要的人^^
相关好文推荐:
通过元学习Agent记忆设计学习如何持续学习 | Yiming Xiong
超越 RAG 以实现智能体记忆:通过解耦和聚合进行检索 | ICML
你的工作不会消失,它只是不断在你身边逐渐萎缩 | Jan Tegze
一个使用 OpenRouter 的 1 万亿令牌实证研究 | OpenRouter AI
一个月内把编码主力交给 Agent 的真实体验 | karpathy
从 DeepSeek V3 到 Mistral 3 Large:现代大语言模型(LLM)架构设计概览(三)| Sebastian Raschka
从 DeepSeek V3 到 Mistral 3 Large:现代大语言模型(LLM)架构设计概览(二)| Sebastian Raschka
从 DeepSeek V3 到 Mistral 3 Large:现代大语言模型(LLM)架构设计概览(一)| Sebastian Raschka
递归语言模型(Recursive Language Models) | Alex Zhang
0条留言