深入解析 Claude Code
如果你把 Claude Code 看成“一个会写代码的模型”,那你大概率会低估它。
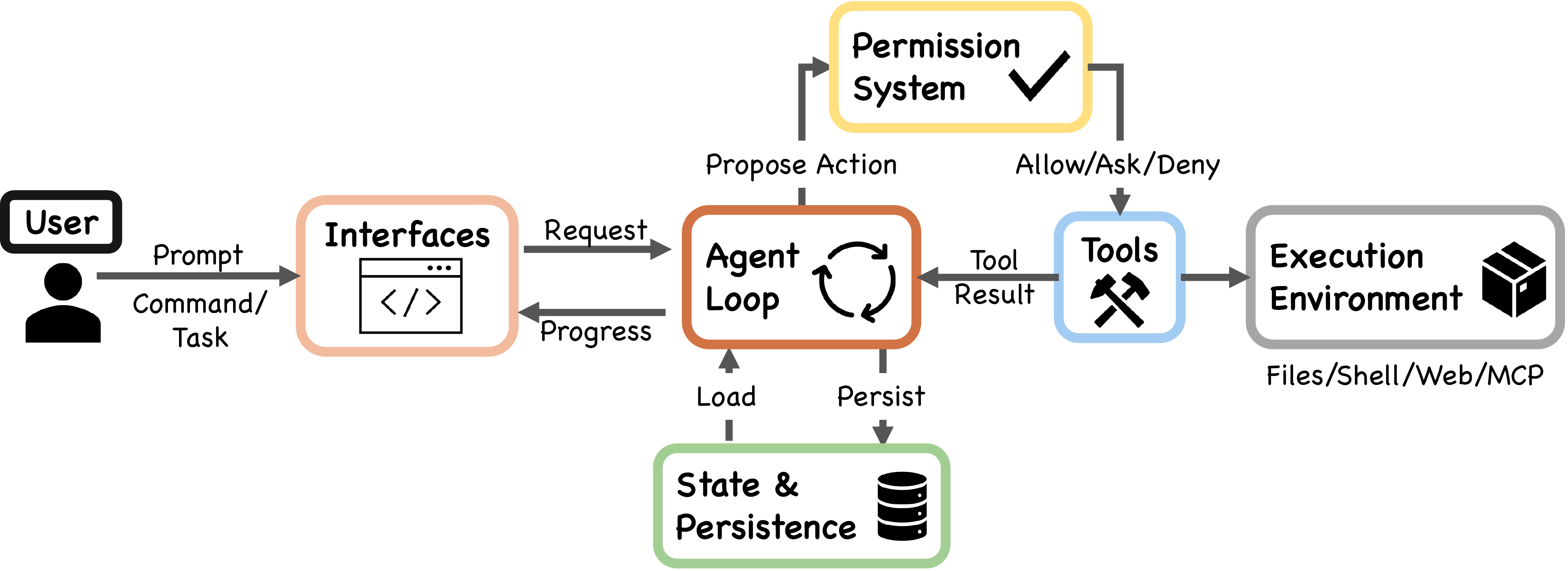
从源码层面看,Claude Code 最值得研究的部分,并不是“模型到底有多聪明”,而是它如何把一个本来并不可靠、也并不天然安全的大模型,包装成一个能在终端里持续工作、调用工具、修改文件、处理中断、恢复会话、管理权限的生产级 agent 系统。
这也是 Claude Code 真正有意思的地方:它的难点,不在模型本身,而在模型之外。
根据对 Claude Code v2.1.88 的源码级分析,这个系统大约包含 1,900 个 TypeScript 文件、约 51.2 万行代码。一个非常抓人的结论是:其中只有约 1.6% 可以归为 AI 决策逻辑,剩下的 98.4% 都是确定性的基础设施。这些基础设施负责权限控制、上下文压缩、工具调度、错误恢复、状态持久化,以及围绕 agent 执行过程的一整套“护栏系统”。
这意味着一件事:如果你想理解今天最强的一类 coding agent 是怎么工作的,关注点不应该只放在 prompt、模型参数和 tool calling 上,而应该放在更底层的系统设计上。
一、Claude Code 到底解决了什么问题?
任何一个真正可用的 coding agent,最终都得回答四个问题:
-
1. 推理到底放在模型里,还是放在系统里? -
2. 模型获得怎样的工具能力,才能既强大又不失控? -
3. 当它开始持续执行时,如何保证安全、稳定和可恢复? -
4. 当上下文越来越长、任务越来越复杂时,系统怎么避免失控膨胀?
Claude Code 对这四个问题的回答非常明确。
第一,推理由模型承担,但约束由 harness 承担。也就是说,模型负责“想”,系统负责“管”。
第二,整个系统只有一个核心执行引擎,也就是统一的 queryLoop,CLI、SDK、IDE 都围绕它展开。
第三,默认安全策略不是“先放行再补救”,而是 deny-first,也就是先拒绝、再询问、最后才允许。
第四,系统从设计之初就把上下文窗口视为稀缺资源,因此在每次模型调用前都要做多层压缩和整形。
如果把这些答案放在一起看,你会发现 Claude Code 的设计倾向非常鲜明:它不是把 agent 当成一个“会自动做事的聊天机器人”,而是把它当成一个长时间运行、需要被精密约束的执行系统。
二、Claude Code 最反直觉的一点:核心循环其实很简单
很多人第一次接触 agent 系统时,容易把重点放在“循环”上,比如 ReAct、Plan-Act、Observe-Reflect 这些范式,好像 agent 的秘密都藏在那段循环代码里。
但 Claude Code 恰好说明了相反的事实。
它的核心 agent loop,本质上就是一个遵循 ReAct 模式的 while 循环:
组装上下文 → 调用模型 → 分发工具 → 检查权限 → 执行工具 → 判断是否继续下一轮。
这个循环本身并不复杂,甚至可以说相当朴素。真正复杂的是这条循环前后附着的系统能力。
比如,在每次模型调用之前,Claude Code 都会执行一套分级压缩流水线,包括:
-
• Budget Reduction • 预算削减 -
• Snip • 截断 -
• Microcompact • 微紧凑 -
• Context Collapse • 上下文坍塌 -
• Auto-Compact • 自动紧凑
这几层机制不是“锦上添花”的优化,而是系统可以长期运行的前提。因为一旦 agent 能持续工作,它的上下文就会快速膨胀;如果没有分层压缩,系统很快就会退化成一个上下文爆炸、性能下降、行为不可预期的工具。
同样,工具执行也不是简单地“模型说调哪个工具就调哪个工具”。Claude Code 至少区分了两条执行路径:
-
• 一条是流式执行路径 StreamingToolExecutor,它会在工具调用流出来时尽早启动执行,目标是压低延迟。 -
• 另一条是回退路径 runTools,它会把工具分为可并发执行和必须独占执行两类,再决定调度方式。
换句话说,模型只决定“我想做什么”,但真正“怎么做、何时做、能不能做、失败了怎么办”,都交给外围系统处理。
这也解释了为什么源码分析会得出那个结论:1.6% 是 AI,98.4% 是基础设施。
三、真正拉开差距的,是安全系统而不是工具数量
如果只看表层功能,Claude Code 并不是唯一一个“会调用 shell、会读写文件、会跑命令”的 agent。很多开源项目也能做到这些。
但真正的差距,往往出现在安全设计上。
Claude Code 的权限体系并不是一个单点开关,而是一条渐进式信任谱系。系统中包含 plan、default、acceptEdits、auto、dontAsk、bypassPermissions 等多种模式,背后对应的是不同强度的人类监督。
更重要的是,它采用了非常明确的 deny-first 机制:更宽泛的 deny,会覆盖更具体的 allow。也就是说,这个系统默认假设“误放行”比“误阻止”更危险。
从架构角度看,Claude Code 不是依赖一层权限提示来保证安全,而是采用了 7 层独立防护,从工具预过滤、规则求值、hook 拦截,一直到 shell 沙箱。你可以把它理解为一种典型的纵深防御思路。
但这里还有一个更有价值的观察:论文和源码分析并没有把“多层防御”神化,反而明确指出,纵深防御也会失败,尤其当不同安全层共享相同的性能约束和执行瓶颈时。
其中一个很典型的例子是子命令解析。如果某些安全检查依赖逐个解析子命令,而这件事本身又会导致事件循环阻塞,那么一旦命令过长,系统反而可能为了避免卡死而跳过分析。也就是说,安全层数增加,并不自动等于更安全;如果这些层共享失败模式,它们会一起失效。
这是一种很成熟的工程视角:真正值得警惕的,从来不是“有没有安全机制”,而是“这些安全机制在压力条件下会不会同时坏掉”。
四、Claude Code 的一个关键启发:权限不是一次性授予,而是持续协商
传统软件权限设计,通常更像静态开关。你授权了,它就一直有;你没授权,它就一直没有。
Claude Code 不是这样。
它更像是在构造一套“动态信任关系”。用户并不是一次性把全部权限永久授予 agent,而是在会话中逐步建立信任,并且这种信任不会在恢复会话时被自动继承。
这一点非常重要。Claude Code 明确规定:权限在 resume 时不会自动恢复,必须重新建立。
从产品角度看,这会让体验变“麻烦”一点;但从系统安全角度看,这种设计非常合理。因为一个 agent 一旦能够跨会话自动继承高权限,它就不再只是一个临时助手,而会逐步接近一个长期常驻、可积累权限的执行主体。那时风险模型就完全变了。
这也解释了 Claude Code 为什么对“auto mode”如此谨慎。它并不是简单地跳过用户确认,而是引入一个额外的分类器,去判断哪些行为可以自动放行、哪些不行。也就是说,即使在“自动化”模式下,系统仍然在尽量把决策拆分为多个环节,而不是让一个模型单独拍板。
五、如果说模型是大脑,那么 Claude Code 的真正价值在“躯干”
Claude Code 的另一个值得关注的设计,是它对扩展机制的分层处理。
它并不是把所有扩展能力都当成同一类东西,而是明确区分为 Hooks、Skills、Plugins 和 MCP,并且这些机制对应不同的上下文成本和注入位置。
这是一个很有启发的架构思路。
在很多 agent 系统里,“扩展”会被抽象成统一插件接口,听起来很优雅,但实际运行时代价极高。因为不同扩展进入系统的方式不同:有些只是影响上下文组装,有些决定模型可见内容,有些直接影响动作执行。它们既不应该走同一条路径,也不应该消耗同样的 token 成本。
Claude Code 把扩展的注入点拆成了三个问题:
-
• assemble():模型到底能看到什么 -
• model():模型到底能访问什么 -
• execute():动作到底能不能执行、怎么执行
这套拆分非常重要,因为它让“扩展”不再只是功能加法,而变成了架构中的一等公民。你可以在不破坏主循环的情况下,为系统增加能力;同时又不会把所有机制都粗暴塞进同一个上下文窗口。
六、它对上下文问题的处理,比很多人想得更保守也更现实
今天很多 agent 产品谈“长上下文”,会给人一种错觉:只要模型窗口足够大,很多系统问题就能自动消失。
Claude Code 的设计刚好说明,这种想法过于乐观。
即使在上下文窗口已经很大的前提下,它依然把上下文当成极其稀缺的资源来处理,并围绕这一点建立了一整套保守机制。
比如,它的上下文不是随手拼接出来的,而是来自多个有序来源。像 CLAUDE.md 这样的内容,也不是被塞进 system prompt 里强制执行,而是作为用户上下文传入。这意味着系统承认一个现实:很多开发规则和项目记忆,本质上是“高优先级提示”,但不是绝对不可违背的内核指令。
它的记忆系统也没有走今天很流行的向量数据库路线,而是采用基于文件的可见记忆。换句话说,记忆不是一个黑盒检索层,而是用户可以检查、编辑、版本控制的真实文件系统资产。
这种做法看似“不够先进”,但它有两个巨大优势。
第一,透明。你知道 agent 记住了什么,也知道它是从哪里取出来的。
第二,可控。你可以像维护代码一样维护记忆,而不是把行为寄托在一个不可解释的 embedding 检索结果上。
从工程实践看,这种取舍非常合理。很多时候,生产系统最怕的不是“能力不够强”,而是“能力看起来很强,但行为不可解释、不可调试、不可审计”。
七、子代理不是为了炫技,而是为了解决上下文爆炸
Claude Code 支持多种子代理类型,也支持通过 .claude/agents/*.md 自定义 agent。这看起来很先进,但它真正解决的问题其实非常朴素:主上下文不能无限增长。
子代理机制最核心的一点,不是“把任务拆给多个 agent”,而是“只把摘要带回主线程”。
这件事很关键。
如果父代理完整吸收每个子代理的全部执行过程,那么多代理协作很快就会变成上下文灾难。Claude Code 的做法是把子代理运行在隔离边界内,最后只返回摘要,从而保护父代理的上下文预算。
这说明它对多代理的理解并不是“越多越强”,而是“什么时候该隔离,什么时候该回收信息密度”。这是一种非常偏系统工程的思路。
同样值得注意的是,子代理不只是上下文隔离,还是权限隔离。也就是说,多代理架构在这里并不只是并发工具,而是风险隔离工具。
八、会话持久化的重点不是“记住更多”,而是“可审计”
很多人一谈 agent 的持久化,第一反应是“能不能跨会话记住更多内容”。Claude Code 的答案并不是单纯追求“记住”,而是优先追求“能追溯、能修补、能审计”。
它的会话持久化通道包括追加式 JSONL transcript、全局 prompt 历史和子代理侧链。这里最值得注意的不是存储介质,而是设计哲学:只追加、尽量不破坏、在读取时修补。
比如压缩边界会记录 headUuid、anchorUuid、tailUuid,读取时再把消息链补起来,而不是在落盘时把旧内容粗暴覆盖掉。
这背后的思路很清楚:一旦 agent 变成持续工作的系统,日志和状态不只是“为了恢复运行”,也是为了事后解释它为什么这么做。
这是一种典型的生产系统思维。系统历史不只是给机器用的,也是给人审计和排障用的。
九、Claude Code 给今天的 agent 构建者,最重要的启发是什么?
如果只总结一个结论,那就是:
不要把 agent 系统的核心竞争力,误判为“模型循环写得多漂亮”。真正的难点在循环外。
Claude Code 给出的工程启发,至少有以下几点:
1. Harness 比 prompt 更重要
当模型能力不断趋同,真正决定系统差异的,是谁能把模型放进一个更稳、更安全、更可恢复的执行框架里。
2. 安全不是一个按钮,而是一条链路
权限提示、规则系统、hooks、沙箱、分类器,这些都不是可选装饰,而是完整的执行治理系统。缺任何一层,都可能导致系统在真实环境下失控。
3. 上下文必须从第一天开始当成稀缺资源
不要指望“窗口大了问题就没了”。真正有效的做法,是设计一套渐进式退化和压缩机制,让系统在复杂任务中仍然保持稳定。
4. 多代理不是为了更酷,而是为了隔离
子代理的核心价值是控制复杂度和风险边界,而不是表演式分工。什么时候隔离,什么时候只返回摘要,比“能不能多开几个 agent”更重要。
5. 可审计性往往比能力上限更重要
一个偶尔很强、但不可解释的 agent,很难真正进入生产环境。相反,一个能力略保守、但可追踪、可恢复、可治理的系统,更有机会真正被长期使用。
十、为什么说 Claude Code 值得被反复研究?
因为它展示的不是一个“会写代码的 AI 产品”,而是一种新的软件系统形态。
在这种形态里,模型不再是完整产品,而是系统中的一个部件;真正的产品,是围绕模型构建出来的执行约束、状态管理、权限治理、上下文编排和恢复机制。
这也是为什么 Claude Code 这样的系统,远比表面看上去更难复制。
复制一个 while 循环并不难,复制一个 tool calling 框架也不难,甚至复制一套 prompt 模板都不难。真正难的是:你能不能把这些碎片整合成一个能长期运行、能被人信任、能处理失败、能解释自己行为的系统。
从这个角度看,Claude Code 的真正价值不只在于“它怎么做 AI coding”,更在于它向整个行业证明了一件事:
下一代 agent 的竞争,不只是模型能力竞争,而是系统工程能力竞争。
如果你正在做 AI agent、coding assistant,或者任何需要“模型持续执行任务”的产品,那么 Claude Code 最值得学的,不是它用了哪些模型能力,而是它怎样把模型放进了一套足够坚固的工程框架里。
而这,可能才是今天所有 agent 产品最应该补的课。
https://github.com/VILA-Lab/Dive-into-Claude-Code
如果觉得内容不错,欢迎你点一下「在看」,或是将文章分享给其他有需要的人^^
相关好文推荐:
一种快速判别产品AI含量的黄金指标,帮你远离披着AI外皮的传统软件公司
0条留言