AI 的学习,不一定只能靠训练模型
最近看到一篇很有意思的文章:《Learning Beyond Gradients》。
https://trinkle23897.github.io/learning-beyond-gradients/#zh
作者提出了一个非常大胆,但又越来越现实的观点:AI 的“学习”,不一定只能靠梯度下降和训练神经网络。未来的 AI,也可能通过持续修改代码、积累经验、维护规则系统来学习。
这听上去像是在“反深度学习”,但实际上并不是。相反,这篇文章真正有价值的地方在于,它重新定义了“学习”到底是什么。
为什么我们会默认“学习 = 训练模型”?
过去十几年,AI 几乎都是围绕同一种范式展开:
数据 -> 神经网络 -> 梯度下降 -> 更新权重
无论是 ChatGPT、图像识别还是语音识别,底层逻辑都差不多。模型通过大量数据不断调整参数,让输出越来越接近目标答案。
于是慢慢地,我们会默认认为:AI 的学习,本质上就是修改神经网络权重。
但作者提出了一个问题:如果 AI 的学习对象,不是模型参数,而是一整个软件系统呢?
一次很特殊的实验
文章里提到了一类非常有意思的实验。研究者没有训练神经网络策略,而是直接让 Coding Agent 写代码策略。
例如:
if ball_x > paddle_x:
move_right()
else:
move_left()
然后不断循环:
-
• 运行游戏 -
• 观察失败 -
• 修改代码 -
• 再次运行 -
• 继续调整
结果令人意外。在一些强化学习环境中,这种“纯代码策略”居然能达到很高的分数,甚至在 Breakout 里达到了理论最高分。
这里最重要的并不是“规则很强”,而是 Agent 并不是在训练模型,它是在持续维护一个软件系统。
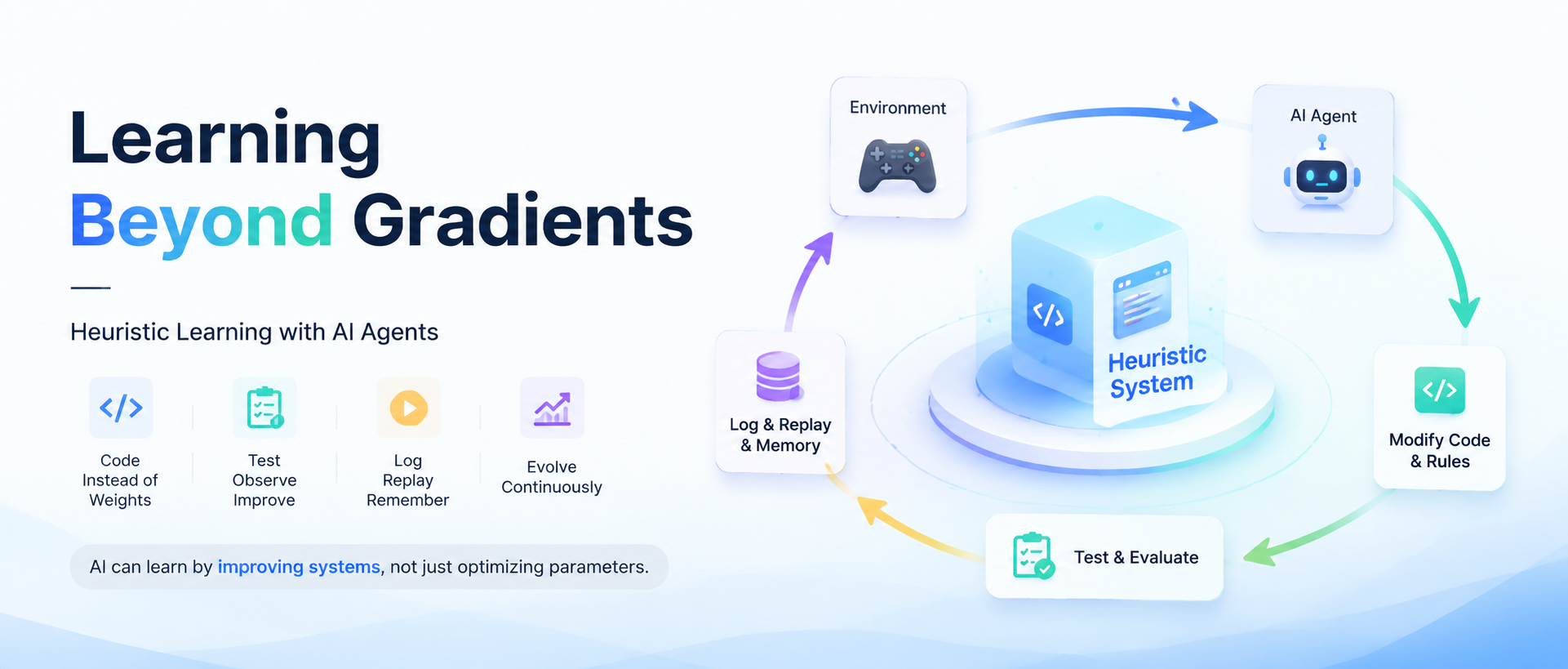
Heuristic Learning:把“学习”变成系统演化
作者把这种方式称为 Heuristic Learning(启发式学习),简称 HL。它维护出来的系统,叫 Heuristic System(启发式系统),简称 HS。
这个系统里包含的东西,不只是代码。还包括日志、回放、测试、失败记录、实验结果、版本 diff、状态分析,以及下一轮优化方向。
也就是说,AI 的“学习结果”,不再只是神经网络里的参数,而是一整套不断进化的软件工程系统。
传统强化学习的流程更像这样:
环境反馈 -> reward -> 更新模型参数
而 HL 更像:
环境反馈
-> agent 分析问题
-> 修改代码
-> 增加测试
-> 记录失败原因
-> 重新运行
-> 总结经验
两者最大的区别在于,Deep RL 的知识隐藏在模型权重里,而 HL 的知识是显式存在的。
比如:
-
• 回归测试 -
• 固定 seed 回放 -
• 失败视频 -
• golden trace -
• 历史 diff -
• bug 总结
这些都会变成系统长期保留下来的“记忆”。
为什么以前没人做成?
因为过去维护规则系统太痛苦。
很多老程序员都见过这种系统:
if xxx:
...
elif xxx:
...
elif xxx:
...
几年后,没有人敢删代码,因为你根本不知道删掉之后会坏哪里。
所以过去专家系统最大的问题,从来不是“规则没用”,而是人类维护不起。
但现在不一样了。因为 Coding Agent 出现了。
过去,增加规则的成本非常高;现在,Agent 可以自动跑测试、自动看日志、自动分析失败、自动修代码、自动比较版本,甚至自动生成总结。
于是,维护复杂规则系统的成本,开始快速下降。
这也是这篇文章真正想表达的东西:过去很多无法扩展的系统,可能不是因为理论错了,而是因为维护成本太高。而 Agent,正在改变这件事。
这其实特别像真正的软件工程
文章里有一个我觉得特别重要的隐含观点。
传统神经网络学习,更像是“把所有经验压进一个黑盒参数空间”。
而 HL 更像是“持续维护一个长期演化的软件项目”。
它不是“训练一个模型然后结束”,而是:
观察问题
-> 修复问题
-> 增加测试
-> 防止回归
-> 沉淀经验
-> 持续迭代
这已经非常接近真正的软件开发流程了。
它真的能取代神经网络吗?
作者并没有这么说。文章里明确提到,HL 不适合解决所有问题。
例如图像识别、复杂感知、高维连续表征,这些仍然是神经网络最擅长的领域。
所以更现实的未来,其实是混合架构:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
简单解析:
-
• 神经网络充当了系统的“感官”和“直觉”。 -
• HL 系统则提供了“理性”框架,负责边界控制。 -
• Agent 是闭环的核心,确保系统不是静态的,而是具备自我进化的能力。
换句话说,未来 AI 可能不是一个模型,而是一个由模型、规则系统、测试系统、长期记忆、回放系统共同组成的“活的软件工程系统”。
为什么这件事值得关注?
因为它可能意味着,AI 的“学习介质”正在改变。
过去:
学习 = 更新参数
未来:
学习 = 修改系统
这其实是一个非常大的思想变化。
它意味着:
-
• 测试也能成为记忆 -
• 日志也能成为经验 -
• 回放也能成为学习数据 -
• 软件架构本身也能持续进化
而 Coding Agent 的角色,也会从“代码生成器”,变成“长期系统维护者”。
最后
这篇文章真正有意思的地方,不是它证明了“规则比神经网络强”。
而是它提出了一种新的可能:
当 Coding Agent 足够强时,代码本身,也可以成为一种“可学习介质”。
未来 AI 的进步,可能不只是“训练更大的模型”,还可能是 Agent 持续维护一个会自我演化的软件系统。
如果觉得内容不错,欢迎你点一下「在看」,或是将文章分享给其他有需要的人^^
相关好文推荐:
一种快速判别产品AI含量的黄金指标,帮你远离披着AI外皮的传统软件公司
0条留言