用 NumPy 看懂 DQN
一直想要系统学习RL的相关知识,脑子里想着能不能完全依靠 Codex 进行学习,于是就有了下面的教程。
完整内容:https://github.com/lanheixingkong/rl-course
前五课已经走过了这样一条线:
Bandit: 先理解动作价值和探索
GridWorld DP: 加入状态、策略、价值,但环境模型已知
Q-learning: 不再提前规划,用经验更新 Q(s,a)
SARSA vs Q-learning: 区分行为策略和学习目标
Function Approximation: Q(s,a) 不一定来自表格,也可以来自函数
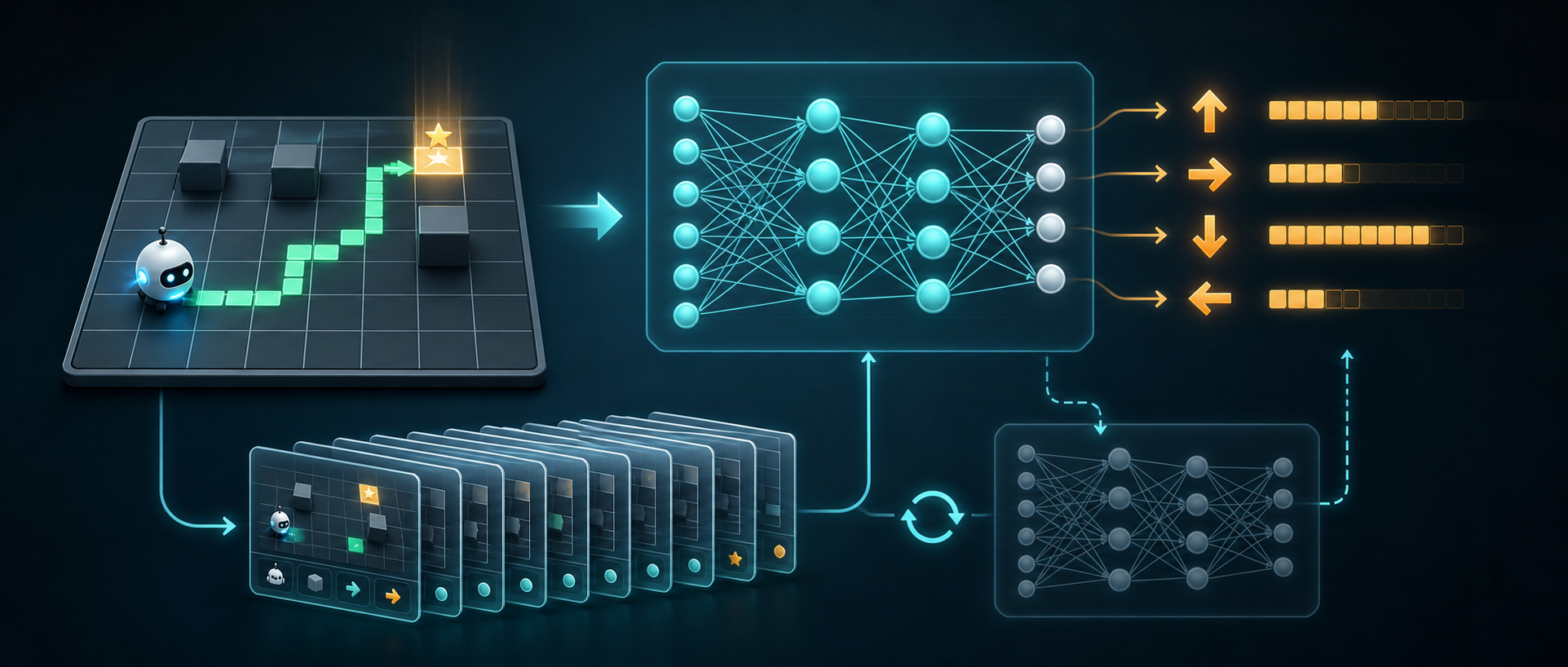
第六课进入 DQN。
很多人第一次看到 DQN,Deep Q-Network(深度 Q 网络),会觉得它突然变成了“深度学习算法”。但从这套课程的脉络看,DQN 不是从零冒出来的东西。
它延续的是第三课以来的同一个核心问题:
如何估计 Q(s,a)?
第三课用 Q 表估计:
q[state][action]
第五课用线性函数估计:
features(state, action) 和 weights
第六课用神经网络估计:
state -> neural network -> Q(s,U), Q(s,R), Q(s,D), Q(s,L)
这就是 DQN 的第一层理解:
DQN = Q-learning + 神经网络函数逼近
但这句话还不完整。DQN 还需要两个稳定训练机制:
replay buffer
target network
本课会用一个纯 NumPy 写的小 DQN,把这三个部分拆开看。
1. 为什么第六课学 DQN
第五课已经说明,Q 表的问题是规模。
如果状态很多,Q 表需要存:
状态数量 * 动作数量
如果状态是图片、连续传感器、用户行为向量,甚至根本不能枚举状态,Q 表就不再合适。
第五课用线性函数过渡:
Q(s,a) = weight_1 * feature_1 + weight_2 * feature_2 + ...
这能减少参数,也能产生泛化。但线性函数表达能力有限。
DQN 的想法是:把这个函数换成神经网络。
Q(s,a) = neural_network(state)[action]
这样模型可以表达更复杂的状态和动作关系。
不过,神经网络越灵活,训练越容易不稳定。所以 DQN 的重点不只是“用了神经网络”,还包括:
如何让神经网络在 RL 里相对稳定地学习。
2. 本课案例
本课仍然使用 GridWorld。
默认地图是 5x5:
start = (4,0)
goal = (0,4)
actions = U, R, D, L
地图中有墙和坑。agent 每走一步会得到 step_reward = -0.04,到达 goal 得到正奖励,掉进 pit 得到负奖励。
这节课的目标不是把 GridWorld 做得复杂,而是看清楚 DQN 的数据流:
state
-> network predicts Q values
-> epsilon-greedy selects action
-> environment returns reward and next_state
-> transition goes into replay buffer
-> sample batch from replay buffer
-> target network computes Q-learning target
-> online network updates parameters
3. 运行代码
如果还没有安装依赖,先运行:
conda activate rl-course
uv pip install -r requirements.txt
本课只需要 NumPy。
然后运行:
python lessons/06_dqn_numpy/dqn_gridworld.py
你会看到类似输出:
NumPy DQN GridWorld config:
rows x cols : 5 x 5
episodes : 1200
max_steps : 80
start_mode : random
hidden_dim : 32
learning_rate : 0.02
gamma : 0.95
epsilon_start/end : 1.0 -> 0.05
epsilon_decay_steps : 2000
replay_capacity : 5000
warmup_steps : 200
batch_size : 32
target_update_steps : 200
episode 200 | avg return last 100: 0.519 | avg steps: 10.8 | success rate: 0.95 | avg loss: 0.01892
episode 1200 | avg return last 100: 0.860 | avg steps: 4.0 | success rate: 0.99 | avg loss: 0.00360
Training summary:
network parameters : 1124
avg return over last 100: 0.860
avg steps over last 100 : 4.0
success rate last 100 : 0.99
avg loss over recent updates : 0.00360
Greedy reachability:
from start (4, 0): goal in 8 steps
from all non-terminal states: 20/20 reach goal
4. 先读输出,不急着看公式
start_mode = random
本课默认每个 episode 从随机非终止状态开始。
原因是:DQN 需要经验数据。如果每局都只从固定起点 (4,0) 开始,有些状态很少被访问,最终策略可能只对起点附近比较好。
随机起点可以让 replay buffer 收集到更全面的经验。
你可以运行:
python lessons/06_dqn_numpy/dqn_gridworld.py --start-mode fixed
对比:
success rate last 100
greedy reachability
这个实验要验证的是:
RL 不是只有算法,数据覆盖也会影响最终策略。
avg return
avg return last 100 是最近 100 局的平均累计奖励。
累计奖励来自每一步 reward 的相加:
-0.04 + -0.04 + ... + goal_reward
如果路径更短、掉坑更少,平均 return 通常更高。
success rate
success rate last 100 是最近 100 局到达 goal 的比例。
它描述的是训练过程中的表现。
注意,它不等于“最终策略从每个格子都能走到 goal”。所以代码还输出:
Greedy reachability
avg loss
avg loss 是神经网络训练误差。
在 DQN 中,网络要拟合一个 Q-learning target:
target = reward + gamma * max Q(next_state, action)
loss 大致表示:
网络当前预测的 Q(s,a) 和 target 差多远。
但是不要把 loss 当成唯一指标。
监督学习里,训练集 loss 下降通常更直接;而 RL 里,target 会随着学习变化,数据分布也会随着 policy 变化。
所以 DQN 要一起看:
return
success rate
loss
最终 greedy policy
5. 查看单步过程
运行:
python lessons/06_dqn_numpy/dqn_gridworld.py --episodes 3 --debug-episodes 1 --log-every 0 --max-steps 15 --warmup-steps 5 --batch-size 4 --epsilon-decay-steps 100
你会看到类似输出:
Episode 1:
step epsilon state action reward next replay loss
1 1.000 (2, 4) L -0.04 (2, 3) 1 -
2 0.991 (2, 3) L -0.04 (2, 2) 2 -
5 0.962 (2, 3) U -0.04 (1, 3) 5 0.0062
这张表说明的是一条经验如何进入 DQN。
|
|
|
|---|---|
step |
|
epsilon |
|
state |
|
action |
|
reward |
|
next |
|
replay |
|
loss |
|
前几步 loss 是 -,因为经验还不够。
代码设置了:
warmup_steps = 5
batch_size = 4
所以当 replay buffer 至少有 5 条经验,并且能抽出 4 条经验组成 batch 时,训练才开始。
6. 代码地图
打开:
lessons/06_dqn_numpy/dqn_gridworld.py
不要从公式开始读。按执行流程读:
main()
-> make_env()
-> train_dqn()
-> choose_action()
-> env.step()
-> replay.append()
-> replay.sample()
-> target_network.predict()
-> online_network.train_step()
-> target_network.copy_from()
-> summarize()
-> print_greedy_policy()
-> print_greedy_reachability()
这个流程对应 DQN 的完整循环。
在继续读具体函数之前,先看清楚状态输入链路:
feature_dim(env)
-> 决定神经网络输入层有多宽
state_features(env, state)
-> 把一个 state 变成一个输入向量
batch_features(env, states)
-> 把一批 state 变成一批输入向量
QNetwork.predict(...)
-> 根据输入向量输出 Q 值
这样读代码会更顺:
先知道网络输入需要多长;
再知道一个 state 如何变成输入;
再看网络如何输出 Q 值。
7. feature_dim:网络输入层有多宽
源码位置:
feature_dim(env)
代码是:
def feature_dim(env: GridWorld) -> int:
return env.rows * env.cols + 5
它不是在计算 Q 值,而是在告诉神经网络:
每个 state_features(env, state) 会产生多少个输入数字。
默认 5x5 地图中:
env.rows * env.cols = 25
这 25 个数字来自 one-hot 位置特征。后面的 + 5 是 5 个辅助特征:
row 位置
col 位置
到 goal 的行方向差距
到 goal 的列方向差距
离 pit 的接近程度
这里的 + 5 不是 RL 或 DQN 的固定公式,而是本课代码里手工设计了 5 个额外输入特征。
如果地图从 5x5 改成 8x8:
one-hot 位置特征数量 = 8 * 8 = 64
辅助特征数量 = 5
输入维度 = 64 + 5 = 69
如果以后你自己增加或减少辅助特征,就必须同步修改 feature_dim()。例如你再增加一个 is_near_wall 特征,辅助特征就从 5 个变成 6 个,feature_dim() 也应该改成:
return env.rows * env.cols + 6
所以 feature_dim() 和 state_features() 必须保持一致:
feature_dim() 返回多少;
state_features() 实际就必须产生多少个数字。
所以默认输入维度是:
25 + 5 = 30
feature_dim 在 train_dqn() 里被使用:
online_network = QNetwork(input_dim=feature_dim(env), hidden_dim=hidden_dim, output_dim=len(ACTIONS), rng=np_rng)
target_network = QNetwork(input_dim=feature_dim(env), hidden_dim=hidden_dim, output_dim=len(ACTIONS), rng=np_rng)
这两行的意思是:online network 和 target network 必须使用同样宽度的输入层,因为它们都会接收同一种 state_features。
8. state_features:状态如何进入网络
源码位置:
state_features(env, state)
神经网络不能直接处理 (row, col) 这种 Python 元组。它需要数字向量。
所以代码把状态变成两部分:
one-hot 位置特征
归一化辅助特征
5x5 地图有 25 个格子。one-hot 的意思是:
当前位置对应的一位是 1;
其他位置都是 0。
这样做的目的:
让网络明确知道 agent 当前在哪个格子。
辅助特征包括:
row 位置
col 位置
到 goal 的行方向差距
到 goal 的列方向差距
离 pit 的接近程度
state_features 有两个主要使用位置。
第一处在 choose_action():
q_values = network.predict(state_features(env, state)[None, :])[0]
这里是单个状态。[None, :] 是把一个输入向量变成一批输入,形状从:
(input_dim,)
变成:
(1, input_dim)
因为 QNetwork.predict() 按 batch 处理输入。
第二处在 batch_features():
def batch_features(env: GridWorld, states: list[State]) -> np.ndarray:
return np.vstack([state_features(env, state) for state in states])
这里是训练时从 replay buffer 抽出一批经验,要把一批 state 和一批 next_state 都变成网络输入:
batch_states = batch_features(env, [transition.state for transition in batch])
batch_next_states = batch_features(env, [transition.next_state for transition in batch])
所以 state_features 不是孤立函数,它连接了 GridWorld 的离散坐标和神经网络的数值输入。
以后如果处理 Atari 游戏画面,输入就可能是一张图片;如果处理机器人控制,输入可能是关节角度、速度和传感器读数。
9. QNetwork:网络输出什么
源码位置:
class QNetwork
这个网络很小:
input -> hidden layer -> ReLU -> output
输出层有 4 个数字:
Q(s,U)
Q(s,R)
Q(s,D)
Q(s,L)
这点非常重要。
DQN 不是输入 (state, action) 后只输出一个 Q 值。本课代码采用常见写法:
输入 state,一次输出这个 state 下所有动作的 Q 值。
这样选择动作时,只需要:
q_values = network.predict(state_features(env, state)[None, :])[0]
然后取最大值对应的动作。
10. choose_action:DQN 仍然需要探索
源码位置:
choose_action(env, network, state, epsilon, rng)
逻辑和第三课一样:
如果随机数 < epsilon,就随机选动作;
否则选择网络预测 Q 值最大的动作。
这说明 DQN 仍然是 RL,不是普通监督学习。
它必须通过行动收集数据,而行动策略会影响之后看到的数据。
11. train_dqn 的一步循环
源码位置:
train_dqn() 里的 for step_index in range(1, max_steps + 1):
这层循环表示:
在一个 episode 里,agent 最多和环境交互 max_steps 次。
每一次循环都完成一整步 DQN 流程:
算当前 epsilon
选择动作
执行动作得到经验
把经验放入 replay buffer
如果经验足够,就抽 batch 训练 online_network
必要时同步 target_network
如果到达终止状态,就结束本 episode
先看前两行:
progress = min(1.0, total_steps / max(1, epsilon_decay_steps))
epsilon = epsilon_start + progress * (epsilon_end - epsilon_start)
它们的作用是让探索概率 epsilon 从大逐渐变小。
默认参数是:
epsilon_start = 1.0
epsilon_end = 0.05
epsilon_decay_steps = 2000
含义是:
训练刚开始时,epsilon = 1.0,几乎完全随机探索;
随着 total_steps 增加,epsilon 逐渐下降;
到 2000 个环境步以后,epsilon 降到 0.05;
之后保持 0.05,不再继续下降。
progress 表示当前衰减进度:
total_steps = 0 -> progress = 0.0
total_steps = 1000 -> progress = 0.5
total_steps >= 2000 -> progress = 1.0
min(1.0, ...) 是为了限制最大进度不超过 1.0。否则训练超过 epsilon_decay_steps 后,epsilon 会继续下降,甚至可能低于 epsilon_end。
max(1, epsilon_decay_steps) 是为了避免有人把 epsilon_decay_steps 设成 0 时发生除以 0。
第二行:
epsilon = epsilon_start + progress * (epsilon_end - epsilon_start)
是线性插值。因为 epsilon_end - epsilon_start 是负数,所以 epsilon 会从 epsilon_start 逐渐下降到 epsilon_end。
例如默认值下:
progress = 0.0 -> epsilon = 1.0
progress = 0.5 -> epsilon = 0.525
progress = 1.0 -> epsilon = 0.05
为什么要这么做?
因为 DQN 一开始什么都不知道,需要多探索;后面网络已经学到一些 Q 值,就应该更多利用当前知识,但仍保留少量随机探索,避免完全卡在某条错误路径里。
接下来选择并执行动作:
action_index = choose_action(env, online_network, state, epsilon, rng)
action = ACTIONS[action_index]
next_state, reward, done = env.step(state, action, rng)
这里仍然是 epsilon-greedy:
有 epsilon 的概率随机选动作;
否则用 online_network 预测 Q 值,选择 Q 最大的动作。
然后保存经验并更新统计:
replay.append(Transition(state, action_index, reward, next_state, done))
total_reward += reward
total_steps += 1
total_reward 用来统计本 episode 的累计奖励;total_steps 是整个训练过程累计走了多少环境步,它会影响 epsilon 衰减和 target network 同步时机。
后面的训练块:
if len(replay) >= warmup_steps and len(replay) >= batch_size:
batch = replay.sample(batch_size)
...
loss = online_network.train_step(batch_states, batch_actions, targets, learning_rate)
意思是:先收集足够经验,再开始训练神经网络。
最后更新状态并检查 episode 是否结束:
state = next_state
if done:
break
如果 done = True,说明到达 goal 或 pit,这一局就结束。
12. ReplayBuffer:经验回放
源码位置:
class ReplayBuffer
每一步交互得到一条经验:
(state, action, reward, next_state, done)
这条经验会被保存:
replay.append(Transition(state, action_index, reward, next_state, done))
训练时,代码随机抽 batch:
batch = replay.sample(batch_size)
为什么不只用最新一步?
因为连续经验高度相关。
假设 agent 正在从左下角连续往右走,最近几步经验可能是:
(4,0) --R--> (4,1)
(4,1) --R--> (4,2)
(4,2) --R--> (4,3)
这些经验很像:状态相邻、动作相似、reward 也差不多。
如果神经网络按这种顺序连续训练,就容易出现三个问题:
1. 一个 batch 里的信息很重复,像是在反复学习同一小段路;
2. 网络参数会被最近这条轨迹强烈影响,容易忘掉其他区域的经验;
3. DQN 的 target 本来就依赖 Q 值,连续偏向同一类样本会让更新更容易波动。
随机采样的目的就是把不同时间、不同位置、不同结果的经验混在一起:
有的来自起点附近;
有的来自 goal 附近;
有的来自 pit 附近;
有的是成功路径;
有的是失败路径。
这样每次训练的 batch 更像一个小型混合数据集,网络更新方向不会只被最近几步牵着走。
所以 replay buffer 的作用是:
保存过去经验;
随机抽样;
重复利用;
降低连续样本相关性。
13. target 是怎么算出来的
源码位置:
train_dqn() 中的 targets = ...
核心代码:
next_q = target_network.predict(batch_next_states)
targets = batch_rewards + gamma * (1.0 - batch_dones) * np.max(next_q, axis=1)
这和第三课 Q-learning 的 target 是同一个结构:
target = reward + gamma * max_a Q(next_state, a)
区别是:
第三课的 Q 来自表;
第六课的 Q 来自神经网络。
如果 done = True,说明已经到达 goal 或 pit,不再有未来价值:
target = reward
所以代码用:
(1.0 - batch_dones)
把终止状态后面的未来项去掉。
14. 为什么需要 target network
DQN 有两个网络:
|
|
|
|---|---|
online_network |
|
target_network |
|
这两个网络结构相同,输入维度、隐藏层宽度、输出维度都一样。
刚创建时,代码先创建两个网络:
online_network = QNetwork(input_dim=feature_dim(env), hidden_dim=hidden_dim, output_dim=len(ACTIONS), rng=np_rng)
target_network = QNetwork(input_dim=feature_dim(env), hidden_dim=hidden_dim, output_dim=len(ACTIONS), rng=np_rng)
然后立刻同步参数:
target_network.copy_from(online_network)
这一步的意思是:
target_network 从 online_network 的同一套初始权重开始。
训练过程中,真正被梯度下降更新的是 online_network:
loss = online_network.train_step(batch_states, batch_actions, targets, learning_rate)
target_network 不会单独调用 train_step(),所以它不会自己训练。
如果 target 也用 online network 计算,就会出现:
模型正在追一个由自己实时改变的目标。
这会让学习更不稳定。
所以代码每隔一段时间复制一次参数:
if total_steps % target_update_steps == 0:
target_network.copy_from(online_network)
所以 target network 的参数来源是:
由 online_network 训练;
每隔 target_update_steps 步复制给 target_network。
为什么不让 target_network 也单独训练?
因为它的职责不是学习一个新的 Q 函数,而是提供一个慢变化的 target 计算器。
DQN 的学习目标是:
target = reward + gamma * max target_network(next_state)
如果 target_network 也每一步单独训练,那么 online network 和 target network 都在快速变化,学习目标会重新变得不稳定。
所以 DQN 故意让它“慢半拍”:
online_network 持续学习;
target_network 暂时固定;
隔一段时间再复制 online_network 的权重。
这相当于让学习目标慢一点变化。
15. train_step:神经网络负责拟合 target
源码位置:
QNetwork.train_step()
这一段做的是神经网络训练。
先计算网络当前预测:
prediction = Q(s,a)
再和 Q-learning target 比较:
error = prediction - target
loss = error^2
然后反向传播,更新参数。
在本课你不需要背每个矩阵求导。只要抓住:
RL 部分负责产生 target;
神经网络部分负责拟合 target。
这就是看懂 DQN 代码的关键。
16. 能不能把 DQN 理解成普通神经网络训练?
可以这样入门理解:
DQN 的神经网络训练部分,确实很像普通神经网络训练。
对应关系是:
|
|
|
|---|---|
|
|
state_features(state) |
|
|
online_network
Q(s,a)
|
|
|
reward + gamma * max target_network(next_state) |
|
|
|
|
|
online_network.train_step(...) |
但这个类比有三个重要限制。
第一,DQN 的训练数据不是提前准备好的固定数据集,而是 agent 和环境交互时实时产生的:
state, action, reward, next_state, done
这些经验先进入 replay buffer,再被随机抽样训练。
第二,每个 step 从 replay buffer 抽一个 batch 后,通常只做一次梯度更新。这更像一次 mini-batch update,不应该叫一个 epoch。
在监督学习里,epoch 通常表示:
把整个训练集完整遍历一遍。
DQN 这里没有固定训练集,也不会每一步完整遍历 replay buffer。
第三,DQN 的 target 不是人工标注的真实标签,而是用奖励和 target network 临时算出来的学习目标:
target = reward + gamma * max target_network(next_state)
这个 target 会随着训练变化,所以它更像“当前算法构造出来的训练目标”,不是监督学习里稳定不变的标签。
所以更准确的理解是:
DQN = 在线收集经验 + replay buffer 抽 mini-batch + target network 构造 target + 普通神经网络梯度更新。
17. DQN 和前几课的关系
|
|
|
|
|---|---|---|
|
|
Q(s,a) |
|
|
|
Q(s,a) |
|
|
|
Q(s,a) |
|
|
|
Q(s,a) |
|
DQN 的目标没有变:
仍然希望学到能带来高累计奖励的动作价值。
变化的是表示能力和训练机制。
18. 这就是全部 DQN 内容吗?
不是。
本课讲的是 DQN 的最小核心版本:
Q-learning target
神经网络估计 Q(s,a)
replay buffer
target network
epsilon-greedy 探索
这些是理解 DQN 的骨架。学会本课之后,你应该能看懂 DQN 代码的大方向:
网络如何输出 Q 值?
经验如何进入 replay buffer?
target 如何计算?
target network 什么时候同步?
online network 如何更新?
但本课还没有覆盖完整 Atari DQN 的所有工程细节。
DeepMind 用来玩 Atari 的 DQN 和本课是同一类方法:都用神经网络估计 Q 值,都使用 replay buffer 和 target network。
但 Atari 版本面对的是游戏画面,所以还多了很多内容:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
所以更准确地说:
本课是 DQN 的教学版骨架;
DeepMind Atari DQN 是同一思想在像素游戏上的完整工程版本。
后面如果继续扩展,可以做一课:
从本课 NumPy DQN 迁移到 PyTorch DQN
再做一课:
从状态向量输入迁移到图像输入和卷积网络
19. 参数实验
实验 1:固定起点和随机起点
python lessons/06_dqn_numpy/dqn_gridworld.py --start-mode fixed
python lessons/06_dqn_numpy/dqn_gridworld.py --start-mode random
问题:
训练数据覆盖会不会影响最终策略?
实验 2:更大的地图
python lessons/06_dqn_numpy/dqn_gridworld.py --rows 8 --cols 8 --episodes 400 --log-every 200
你可能会看到成功率提升,但最终 greedy policy 仍有一些状态走不通。
这说明:
DQN 有更强表达能力,但也不是自动稳定。
更大的地图需要更多经验、更合适的探索、更稳定的参数。
实验 3:target network 更新频率
python lessons/06_dqn_numpy/dqn_gridworld.py --target-update-steps 20
python lessons/06_dqn_numpy/dqn_gridworld.py --target-update-steps 1000
更新太快,target 变化频繁;更新太慢,target 可能跟不上 online network。
实验 4:replay buffer 大小
python lessons/06_dqn_numpy/dqn_gridworld.py --replay-capacity 100 --warmup-steps 20
python lessons/06_dqn_numpy/dqn_gridworld.py --replay-capacity 10000 --warmup-steps 500
经验太少,训练容易受最近轨迹影响;warmup 太大,学习启动会更晚。
实验 5:学习率
python lessons/06_dqn_numpy/dqn_gridworld.py --learning-rate 0.005
python lessons/06_dqn_numpy/dqn_gridworld.py --learning-rate 0.08
学习率太小可能学得慢;学习率太大可能让 loss 和策略更波动。
20. 这一课最容易误解的点
误解 1:DQN 就是把 Q 表换成神经网络
不完整。
更准确地说:
DQN = Q-learning target + 神经网络拟合 + replay buffer + target network
误解 2:loss 越低,策略一定越好
不一定。
RL 里的 target 会变化,数据也由当前策略收集。loss 是一个重要信号,但不是唯一目标。
误解 3:DQN 一定比 Q 表好
不一定。
在小离散问题里,Q 表可能更稳定、更直接。
DQN 的优势主要出现在:
状态空间很大;
状态不能简单枚举;
需要从特征、向量或图像中学习价值。
误解 4:用了神经网络就不需要探索
仍然需要。
DQN 仍然通过行动收集经验。如果没有探索,replay buffer 里的数据会很偏。
21. 过关检查
学完本课后,你应该能回答:
-
1. DQN 和 Q-learning 的关系是什么? -
2. DQN 中神经网络输入什么,输出什么? -
3. 为什么本课网络一次输出四个 Q 值? -
4. replay buffer 保存的是什么? -
5. 为什么训练时要随机抽 batch? -
6. online network 和 target network 的区别是什么? -
7. target 是用哪个网络算出来的? -
8. 为什么 DQN 的 loss 不能单独代表策略好坏? -
9. 为什么更大的地图可能让默认 DQN 失败? -
10. 为什么 DQN 仍然属于 RL,而不是普通监督学习?
22. 总结
第六课的核心结论是:
DQN 仍然是在学习 Q(s,a)。
只是 Q 值不再来自表格,而是来自神经网络。
DQN 的训练可以拆成两句话:
Q-learning 产生 target。
神经网络拟合 target。
为了让这个过程更稳定,DQN 使用:
replay buffer
target network
这节课之后,再看别人写的 DQN 代码时,不要先被框架细节挡住。先找四件事:
网络如何输出 Q 值?
经验如何进入 replay buffer?
target 如何计算?
target network 什么时候更新?
只要这四件事能看懂,大多数 DQN 变体就有了阅读入口。
如果觉得内容不错,欢迎你点一下「在看」,或是将文章分享给其他有需要的人^^
相关好文推荐:
0条留言