ChatGPT在做什么...为什么它会有效?(九)
Inside ChatGPT
ChatGPT内部结构
OK, so we’re finally ready to discuss what’s inside ChatGPT. And, yes, ultimately, it’s a giant neural net—currently a version of the so-called GPT-3 network with 175 billion weights. In many ways this is a neural net very much like the other ones we’ve discussed. But it’s a neural net that’s particularly set up for dealing with language. And its most notable feature is a piece of neural net architecture called a “transformer”.
好的,我们终于可以讨论一下 ChatGPT 的内部结构了。没错,它最终是一个巨大的神经网络——目前被称为GPT-3网络的版本,共有1750 亿个权重。在许多方面,这是一个非常类似于我们讨论过的其他神经网。但这是一个特别为处理语言问题而设计的神经网络。其中最显著的特征是一个被称为 "transformer" 的神经网络架构。
In the first neural nets we discussed above, every neuron at any given layer was basically connected (at least with some weight) to every neuron on the layer before. But this kind of fully connected network is (presumably) overkill if one’s working with data that has particular, known structure. And thus, for example, in the early stages of dealing with images, it’s typical to use so-called convolutional neural nets (“convnets”) in which neurons are effectively laid out on a grid analogous to the pixels in the image—and connected only to neurons nearby on the grid.
在前面我们讨论的第一种神经网络中,任何给定层的每个神经元基本上都与前一层的每个神经元相连(至少有一些权重)。但是,如果要处理具有特定已知结构的数据,这种全连接的网络(可能)是过剩的。因此,例如,在处理图像的早期阶段,典型的做法是使用所谓的卷积神经网络(“convnets”),其中的神经元实际上是按照类似于图像中的像素的网格布置,并且只与网格上附近的神经元相连。
The idea of transformers is to do something at least somewhat similar for sequences of tokens that make up a piece of text. But instead of just defining a fixed region in the sequence over which there can be connections, transformers instead introduce the notion of “attention”—and the idea of “paying attention” more to some parts of the sequence than others. Maybe one day it’ll make sense to just start a generic neural net and do all customization through training. But at least as of now it seems to be critical in practice to “modularize” things—as transformers do, and probably as our brains also do.
transformer的想法是对构成文本的token序列进行类似的操作。但是,transformer并不只是在序列中定义一个固定的区域,然后在这个区域内建立神经元之间的连接,而是引入了“注意力”的概念,即对序列的某些部分比其他部分给予“更多地关注”。也许有一天,启动一个通用的神经网络并通过训练进行所有定制会变得有意义。但至少目前来看,“模块化”事物在实践中似乎至关重要,就像transformers所做的那样,这也可能与我们的大脑一样。
OK, so what does ChatGPT (or, rather, the GPT-3 network on which it’s based) actually do? Recall that its overall goal is to continue text in a “reasonable” way, based on what it’s seen from the training it’s had (which consists in looking at billions of pages of text from the web, etc.) So at any given point, it’s got a certain amount of text—and its goal is to come up with an appropriate choice for the next token to add.
好的,那么ChatGPT(或者说,它所基于的GPT-3网络)实际上在做什么呢?请记住,它的总体目标是根据它从训练中看到的文本(即在互联网等地方查看了数十亿页的文本)学习后,以“合理”的方式延续给定的文本。因此,在任何时候,它都有一定数量的文本,它的目标是为下一个要添加的token想出一个适当的选择。
PS:回想一下之前的文章,ChatGPT本质上只是在玩“文字接龙”。
It operates in three basic stages. First, it takes the sequence of tokens that corresponds to the text so far, and finds an embedding (i.e. an array of numbers) that represents these. Then it operates on this embedding—in a “standard neural net way”, with values “rippling through” successive layers in a network—to produce a new embedding (i.e. a new array of numbers). It then takes the last part of this array and generates from it an array of about 50,000 values that turn into probabilities for different possible next tokens. (And, yes, it so happens that there are about the same number of tokens used as there are common words in English, though only about 3000 of the tokens are whole words, and the rest are fragments.)
ChatGPT的操作分为三个基本阶段。首先,它获取到目前为止与文本相对应的tokens序列,并找到代表这些tokens的嵌入向量(即一组数字)。然后,它以“标准的神经网络方式”操作这个嵌入向量,让值"通过"网络中的连续层以生成一个新的嵌入向量(即另一组数字)。接着,它取新嵌入向量的最后一部分,从中生成一个约50,000个值的数组,这些值转换成可能成为下一个token的概率。(是的,碰巧的是,所使用的token数量与英语常用单词的数量差不多,尽管其中只有大约3000个token是完整的单词,其余都是片段。)
PS:你可以简单的将token理解为一个单词,先将一段文本转变为单词列表,然后找到它们的嵌入向量。然后将嵌入向量作为标准神经网络的输入值,输出值是一组新的嵌入向量。最后,通过输出的最后一部分得到可能是下一个单词的概率列表。你就可以从概率列表中挑选一个作为“文字接龙”的单词。
A critical point is that every part of this pipeline is implemented by a neural network, whose weights are determined by end-to-end training of the network. In other words, in effect nothing except the overall architecture is “explicitly engineered”; everything is just “learned” from training data.
关键点在于,这个管道的每个部分都是由神经网络实现的,其权重是通过端到端的网络训练确定的。换句话说,实际上除了整体架构外,没有什么是“明确设计的”;一切都只是从训练数据中“学习”的。
There are, however, plenty of details in the way the architecture is set up—reflecting all sorts of experience and neural net lore. And—even though this is definitely going into the weeds—I think it’s useful to talk about some of those details, not least to get a sense of just what goes into building something like ChatGPT.
然而,架构的设计中有许多细节,其中反映了各种经验和神经网络的传说。而且,尽管谈论细节就像是进入杂草丛中,但我认为了解其中一些细节是有用的,尤其是你想要了解构建一个像 ChatGPT 这样的东西需要什么。
First comes the embedding module. Here’s a schematic Wolfram Language representation for it for GPT-2:
首先是嵌入模块。这里是一个用于GPT-2的Wolfram语言示意图:

The input is a vector of n tokens (represented as in the previous section by integers from 1 to about 50,000). Each of these tokens is converted (by a single-layer neural net) into an embedding vector (of length 768 for GPT-2 and 12,288 for ChatGPT’s GPT-3). Meanwhile, there’s a “secondary pathway” that takes the sequence of (integer) positions for the tokens, and from these integers creates another embedding vector. And finally the embedding vectors from the token value and the token position are added together—to produce the final sequence of embedding vectors from the embedding module.
输入是一个包含n个token的向量(与上一节一样,用1到50,000左右的整数表示)。这些token中的每一个都被(通过单层神经网)转换为一个嵌入向量(GPT-2的长度为768,ChatGPT的GPT-3为12,288)。同时,还有一个 "次要通道",用于获取token的(整数)位置序列,并从这些整数中创建另一个嵌入向量。最后,将token值和token位置的嵌入向量相加,从而得到嵌入模块的最终嵌入向量序列。
Why does one just add the token-value and token-position embedding vectors together? I don’t think there’s any particular science to this. It’s just that various different things have been tried, and this is one that seems to work. And it’s part of the lore of neural nets that—in some sense—so long as the setup one has is “roughly right” it’s usually possible to home in on details just by doing sufficient training, without ever really needing to “understand at an engineering level” quite how the neural net has ended up configuring itself.
为什么只把token值和token位置的嵌入向量加在一起?我认为这没有什么特别的科学依据。只是在尝试了许多不同的方法后,发现这种方法似乎有效。而且,神经网络的传统理论认为,只要设置大致正确,就可以通过足够的训练来慢慢调整细节,而无需真正理解神经网络是如何配置自己的。
Here’s what the embedding module does, operating on the string hello hello hello hello hello hello hello hello hello hello bye bye bye bye bye bye bye bye bye bye:
下面是嵌入模块针对字符串“hello hello hello hello hello hello hello hello hello hello bye bye bye bye bye bye bye bye bye bye”所做的工作:
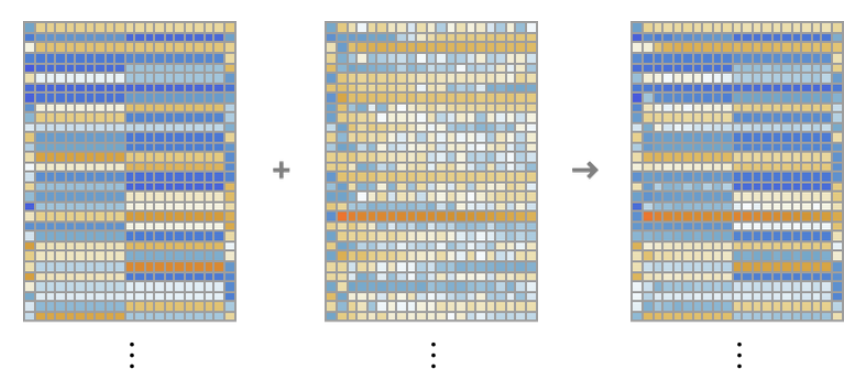
The elements of the embedding vector for each token are shown down the page, and across the page we see first a run of “hello” embeddings, followed by a run of “bye” ones. The second array above is the positional embedding—with its somewhat-random-looking structure being just what “happened to be learned” (in this case in GPT-2).
页面下方展示了每个token的嵌入向量元素,而在页面上方,我们先看到一系列“hello”的嵌入,然后是一系列“bye”的嵌入。上面的第二个数组是位置嵌入——它看起来有点随机的结构只是 "碰巧学到的"(本例中为 GPT-2)。
OK, so after the embedding module comes the “main event” of the transformer: a sequence of so-called “attention blocks” (12 for GPT-2, 96 for ChatGPT’s GPT-3). It’s all pretty complicated—and reminiscent of typical large hard-to-understand engineering systems, or, for that matter, biological systems. But anyway, here’s a schematic representation of a single “attention block” (for GPT-2):
好了,在嵌入模块之后就是transformer的“主事件”:一系列所谓的“注意力块”(GPT-2有12个,ChatGPT的GPT-3有96个)。这些东西相当复杂,让人想起了典型的难以理解的大型工程系统,或者生物系统。但无论如何,下面是单个“注意块”的示意图(对于GPT-2):

Within each such attention block there are a collection of “attention heads” (12 for GPT-2, 96 for ChatGPT’s GPT-3)—each of which operates independently on different chunks of values in the embedding vector. (And, yes, we don’t know any particular reason why it’s a good idea to split up the embedding vector, or what the different parts of it “mean”; this is just one of those things that’s been “found to work”.)
在每个注意力块中,都有一组“注意力头”(GPT-2为12个,ChatGPT的GPT-3为96个)——每个注意力头都独立地对嵌入向量中的不同值块进行操作。(是的,我们不知道为什么要分割嵌入向量,或者它的不同部分有什么 "意义";这只是“被发现有效”的事情之一。)
OK, so what do the attention heads do? Basically they’re a way of “looking back” in the sequence of tokens (i.e. in the text produced so far), and “packaging up the past” in a form that’s useful for finding the next token. In the first section above we talked about using 2-gram probabilities to pick words based on their immediate predecessors. What the “attention” mechanism in transformers does is to allow “attention to” even much earlier words—thus potentially capturing the way, say, verbs can refer to nouns that appear many words before them in a sentence.
好吧,那么注意力头具体做什么呢?基本上,它们是一种在token序列中 "回顾"的方法(即在迄今为止产生的文本中),并将过去的内容 "打包",以便找到下一个token。在文章开始的第一章节,我们讨论了使用 2-gram 概率根据其直接前身来选择单词。transformers中的“注意力”机制允许“注意”更早期的单词——因此有可能捕捉到,比如说,动词可以参考在句子前面与它相隔很远的名词。
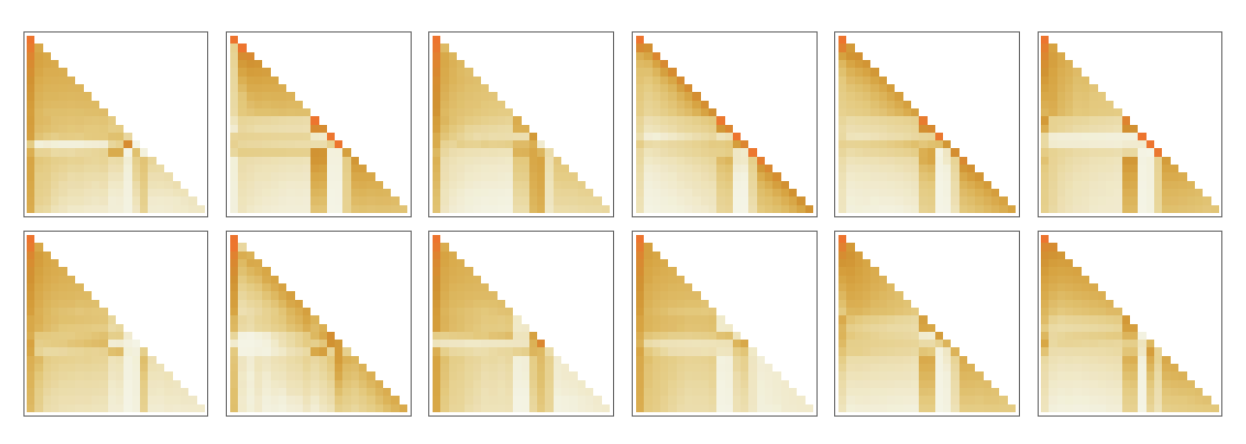
At a more detailed level, what an attention head does is to recombine chunks in the embedding vectors associated with different tokens, with certain weights. And so, for example, the 12 attention heads in the first attention block (in GPT-2) have the following (“look-back-all-the-way-to-the-beginning-of-the-sequence-of-tokens”) patterns of “recombination weights” for the “hello, bye” string above:
更详细地说,一个注意力头的作用是以一定的权重重新组合与不同token相关的嵌入向量的块。因此,例如,第一个注意力块(在GPT-2中),这 12 个注意力头具有以下内容(“look-back-all-the-way-to-the-beginning-of-the-sequence-of-tokens”)上面的“hello,bye”字符串的“重组权重”模式:
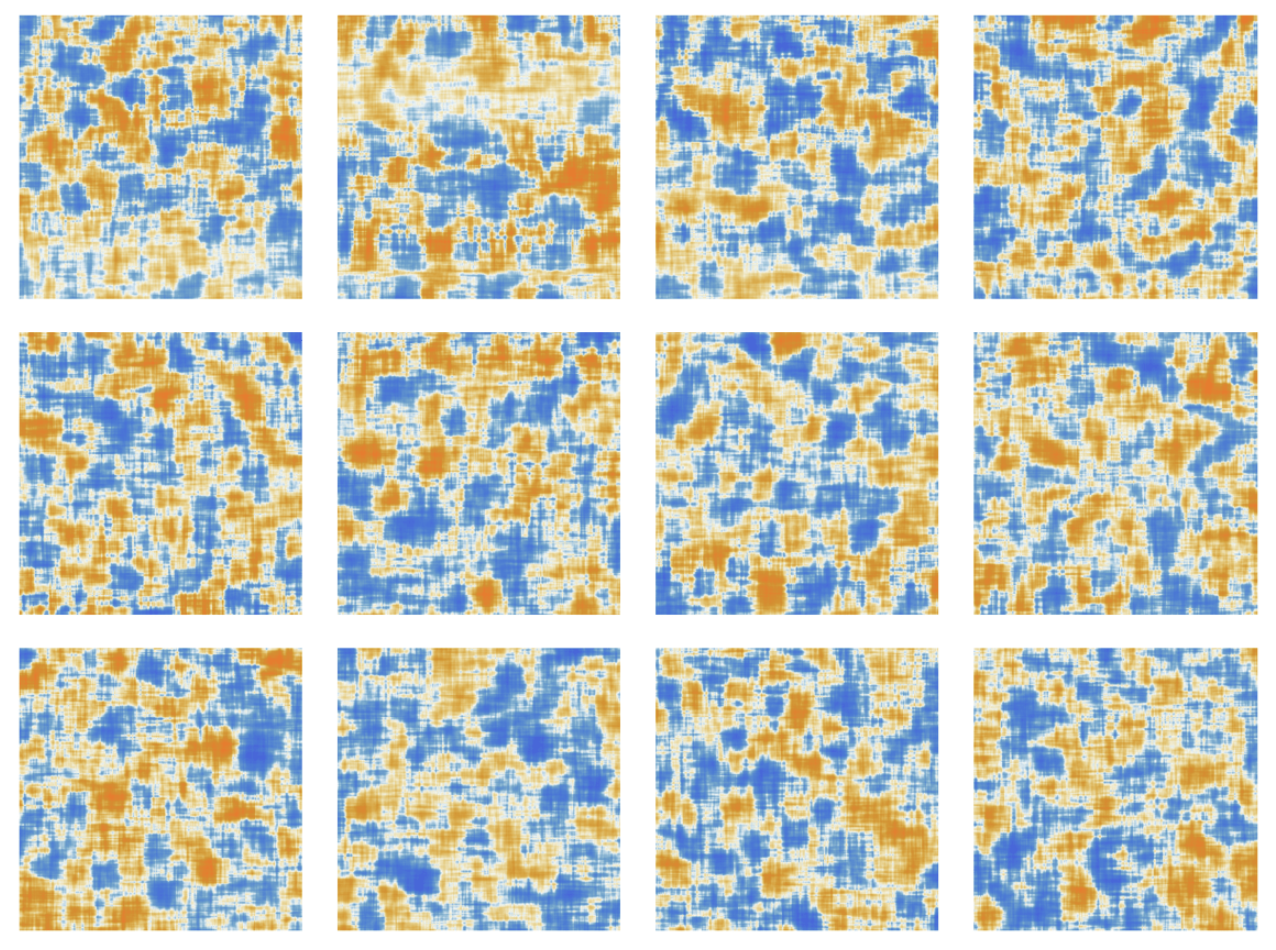
After being processed by the attention heads, the resulting “re-weighted embedding vector” (of length 768 for GPT-2 and length 12,288 for ChatGPT’s GPT-3) is passed through a standard “fully connected” neural net layer. It’s hard to get a handle on what this layer is doing. But here’s a plot of the 768×768 matrix of weights it’s using (here for GPT-2):
经过注意力头的处理之后,得到的“重新加权嵌入向量”(GPT-2的长度为768,ChatGPT的GPT-3的长度为12288)被传递到一个标准的“全连接”神经网络层中。很难理解这一层在做什么。下面是它使用的768×768权重矩阵的绘图(这里是GPT-2的):

Taking 64×64 moving averages, some (random-walk-ish) structure begins to emerge:
采用64×64的移动平均后,一些(类似随机游走的)结构开始出现:

What determines this structure? Ultimately it’s presumably some “neural net encoding” of features of human language. But as of now, what those features might be is quite unknown. In effect, we’re “opening up the brain of ChatGPT” (or at least GPT-2) and discovering, yes, it’s complicated in there, and we don’t understand it—even though in the end it’s producing recognizable human language.
是什么决定了这种结构?它最可能是人类语言特征的一些“神经网络编码”。但目前为止,还不清楚这些特征可能什么。实际上,我们像是正在“打开ChatGPT的大脑”(或者至少是GPT-2的),并发现它的里面很复杂,我们并不理解它——尽管最终它产生了可识别的人类语言。
OK, so after going through one attention block, we’ve got a new embedding vector—which is then successively passed through additional attention blocks (a total of 12 for GPT-2; 96 for GPT-3). Each attention block has its own particular pattern of “attention” and “fully connected” weights. Here for GPT-2 are the sequence of attention weights for the “hello, bye” input, for the first attention head:
好的,在经过一个注意力块之后,我们得到了一个新的嵌入向量,然后再连续通过其他的注意力块(GPT-2有12个,GPT-3有96个)。每个注意力块都有其特定的“注意力”模式和“全连接权重”。这里是GPT-2中第一个注意头对于输入“hello, bye”的注意权重序列:

And here are the (moving-averaged) “matrices” for the fully connected layers:
下面是全连接层的(移动平均)“矩阵”:
Curiously, even though these “matrices of weights” in different attention blocks look quite similar, the distributions of the sizes of weights can be somewhat different (and are not always Gaussian):
奇怪的是,尽管不同注意力块中的这些“权重矩阵”看起来非常相似,但权重的大小分布可能会有所不同(而且不总是高斯分布)。

So after going through all these attention blocks what is the net effect of the transformer? Essentially it’s to transform the original collection of embeddings for the sequence of tokens to a final collection. And the particular way ChatGPT works is then to pick up the last embedding in this collection, and “decode” it to produce a list of probabilities for what token should come next.
那么,在经过了所有的注意力块之后,transformer得到的是什么呢?本质上,它是将原始的token序列的嵌入集合转换为最终的嵌入集合。而ChatGPT的具体工作方式是选择这个集合中的最后一个嵌入向量,并将其“解码”以生成下一个token的概率列表。
So that’s in outline what’s inside ChatGPT. It may seem complicated (not least because of its many inevitably somewhat arbitrary “engineering choices”), but actually the ultimate elements involved are remarkably simple. Because in the end what we’re dealing with is just a neural net made of “artificial neurons”, each doing the simple operation of taking a collection of numerical inputs, and then combining them with certain weights.
这些就是 ChatGPT 内部结构的概要说明。它可能看起来很复杂(尤其是因为它有许多不可避免的、有点随意的 "工程选择"),但实际上它所涉及的最终元素非常简单。因为最终我们所处理的只是一个由“人工神经元”组成的神经网络,每个神经元都会将一组数字输入与某些权重相结合。
The original input to ChatGPT is an array of numbers (the embedding vectors for the tokens so far), and what happens when ChatGPT “runs” to produce a new token is just that these numbers “ripple through” the layers of the neural net, with each neuron “doing its thing” and passing the result to neurons on the next layer. There’s no looping or “going back”. Everything just “feeds forward” through the network.
ChatGPT 的原始输入是一个数字数组(到目前为止token的嵌入向量),当ChatGPT“运行” 以产生新token时,这些数字只是“连续”通过神经网络的层,每个神经元“完成它的任务”后将结果传递给下一层的神经元。没有循环或“回溯”。一切都只是通过网络"向前馈送"。
It’s a very different setup from a typical computational system—like a Turing machine—in which results are repeatedly “reprocessed” by the same computational elements. Here—at least in generating a given token of output—each computational element (i.e. neuron) is used only once.
这是与典型计算系统(如图灵机)非常不同的设置,在这些系统中,结果会被同一计算元素反复“重新处理”。而在这里,至少在生成给定的输出token时,每个计算元素(即神经元)只被使用一次。
But there is in a sense still an “outer loop” that reuses computational elements even in ChatGPT. Because when ChatGPT is going to generate a new token, it always “reads” (i.e. takes as input) the whole sequence of tokens that come before it, including tokens that ChatGPT itself has “written” previously. And we can think of this setup as meaning that ChatGPT does—at least at its outermost level—involve a “feedback loop”, albeit one in which every iteration is explicitly visible as a token that appears in the text that it generates.
但是在某种意义上,ChatGPT 仍然存在一个重复使用计算元素的“外部循环”。因为当 ChatGPT 要生成一个新的token时,它总是“读取”(即作为输入)前面的整个token序列,包括 ChatGPT 自己之前 "写"的token。我们可以认为这种设置意味着 ChatGPT 至少在其最外层涉及一个“反馈循环”,每一次迭代都明确地获得一个token,出现在其生成的文本中。
But let’s come back to the core of ChatGPT: the neural net that’s being repeatedly used to generate each token. At some level it’s very simple: a whole collection of identical artificial neurons. And some parts of the network just consist of (“fully connected”) layers of neurons in which every neuron on a given layer is connected (with some weight) to every neuron on the layer before. But particularly with its transformer architecture, ChatGPT has parts with more structure, in which only specific neurons on different layers are connected. (Of course, one could still say that “all neurons are connected”—but some just have zero weight.)
但是让我们回到 ChatGPT 的核心:被反复用来生成每个token的神经网络。在某种程度上,它非常简单:一个完整的、由相同人工神经元组成的集合。神经网络的某些部分只是由神经元(“全连接”层)组成,其中某一层的每个神经元与前一层的每个神经元相连(通过一些权重)。但是特别是在transformer架构中,ChatGPT 具有更多的结构,其中只有不同层上的特定神经元相连接。(当然,人们仍然可以说“所有神经元都相连”——只是有些权重为零。)
In addition, there are aspects of the neural net in ChatGPT that aren’t most naturally thought of as just consisting of “homogeneous” layers. And for example—as the iconic summary above indicates—inside an attention block there are places where “multiple copies are made” of incoming data, each then going through a different “processing path”, potentially involving a different number of layers, and only later recombining. But while this may be a convenient representation of what’s going on, it’s always at least in principle possible to think of “densely filling in” layers, but just having some weights be zero.
此外,ChatGPT中神经网络的某些方面,并不会最自然地被认为是由“同质”层组成。例如,正如上面的图标摘要所示,在一个注意力块中,有一些地方对传入的数据进行了"多份拷贝",每个拷贝都会经过不同的“处理路径”,可能涉及不同数量的层,然后才重新组合。但是,虽然这可能是对正在发生的事情的一种方便的表述,但至少在原则上,始终可以将它看作是“密集填充”层,只是让一些权重为零。
If one looks at the longest path through ChatGPT, there are about 400 (core) layers involved—in some ways not a huge number. But there are millions of neurons—with a total of 175 billion connections and therefore 175 billion weights. And one thing to realize is that every time ChatGPT generates a new token, it has to do a calculation involving every single one of these weights. Implementationally these calculations can be somewhat organized “by layer” into highly parallel array operations that can conveniently be done on GPUs. But for each token that’s produced, there still have to be 175 billion calculations done (and in the end a bit more)—so that, yes, it’s not surprising that it can take a while to generate a long piece of text with ChatGPT.
如果我们看一下ChatGPT的最长路径,大约有400个(核心)层参与其中,从某种程度上来说这并不是很多。但是其中有数以百万计的神经元——包含了1750 亿个连接,也就是1750亿个权重。需要认识到的一点是,每当 ChatGPT 生成一个新token时,它都必须进行一次涉及每个权重的计算。在实现上,这些计算可以在某种程度上“按层”组织成高度并行的数组操作,方便地在 GPU 上完成。但是,每个生成一个token,仍需要进行 1750 亿次计算(最终可能还要多一点),因此不难理解使用 ChatGPT 生成一段长文本需要花费一段时间。
But in the end, the remarkable thing is that all these operations—individually as simple as they are—can somehow together manage to do such a good “human-like” job of generating text. It has to be emphasized again that (at least so far as we know) there’s no “ultimate theoretical reason” why anything like this should work. And in fact, as we’ll discuss, I think we have to view this as a—potentially surprising—scientific discovery: that somehow in a neural net like ChatGPT’s it’s possible to capture the essence of what human brains manage to do in generating language.
但最终,令人惊奇的是,所有这些操作——虽然它们个别上如此简单——却可以共同完成如此出色的“人类般”的文本生成工作。必须再次强调(至少就我们所知),没有任何“基础理论”可以解释为什么这样的东西会起作用。事实上,正如我们将要讨论的那样,我认为我们必须将其看作是一项(潜在的惊人的)科学发现:在像ChatGPT这样的神经网络中,可以捕捉到人类大脑在生成语言方面所做事情的本质。
这篇文章是我在网上看见的一篇关于ChatGPT工作原理的分析。作者由浅入深的解释了ChatGPT是如何运行的,整个过程并没有深入到具体的模型算法实现,适合非机器学习的开发人员阅读学习。
作者Stephen Wolfram,业界知名的科学家、企业家和计算机科学家。Wolfram Research 公司的创始人、CEO,该公司开发了许多计算机程序和技术,包括 Mathematica 和 Wolfram Alpha 搜索引擎。
本文先使用ChatGPT翻译,再由我进行二次修改,红字部分是我额外添加的说明。由于原文很长,我将原文按章节拆分成多篇文章。想要看原文的朋友可以点击下方的原文链接。
https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/
如果你想亲自尝试一下ChatGPT,可以访问下图小程序,我们已经在小程序中对接了ChatGPT3.5-turbo接口用于测试。

目前通过接口使用ChatGPT与直接访问ChatGPT官网相比,在使用的稳定性和回答质量上还有所差距。特别是接口受到tokens长度限制,无法进行多次的连续对话。
如果你希望能直接访问官网应用,欢迎扫描下图中的二维码进行咨询,和我们一起体验ChatGPT在学习和工作中所带来的巨大改变。


0条留言