Embedding Model 是什么?
这篇文章旨在消除向量、维度等数学词汇的神秘感,将其转化为具体的工程直觉:Embedding 是在为“含义”寻找坐标。
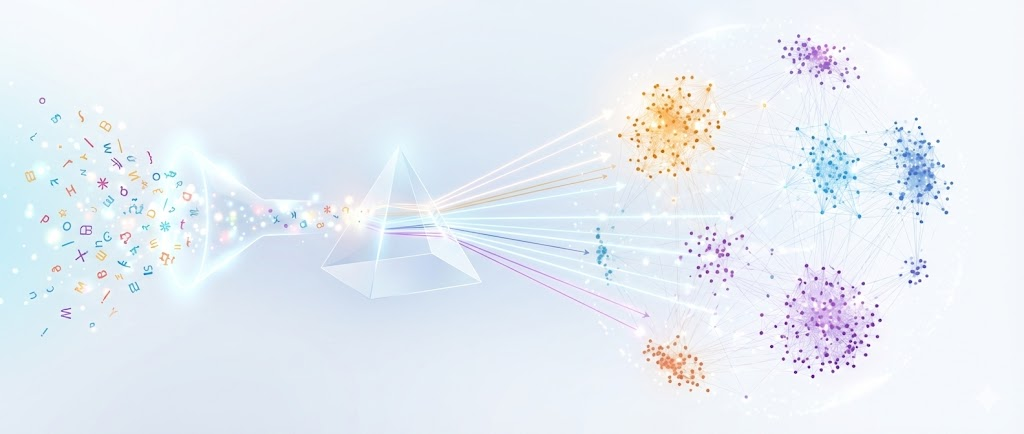
一句话定义:Embedding 是把万物放进同一个坐标系
你可以将 Embedding 理解为一种语义定位服务。无论是词汇、句子、图片还是音视频,经过 Embedding Model 处理后,都会被映射到高维空间中的一个特定点。
这个点的坐标,即表现为一串数字,称为向量 (Vector)。
其核心逻辑在于:Embedding 将万物映射到坐标系中,空间距离越近,语义含义越相似。
这种机制将模糊的“语义”转化为了精确的空间几何关系。
为什么需要 Embedding:计算机不认识“猫”,但认识坐标
人类识别“猫”是通过联想,而计算机原生只识别:
-
• 字符串(如 "猫") -
• Token ID(如 29481) -
• 像素矩阵
这些形式并不包含语义。Embedding 的作用是将“形式”转化为可计算的“位置”。 一旦内容拥有了坐标,计算机就可以通过纯数学手段实现以下功能:
-
• 算距离:评估两个内容的相似度。 -
• 找邻居:检索最相关的上下文。 -
• 聚类:发现数据的天然分布规律。 -
• 语义检索:超越关键词匹配,通过含义寻找答案。
Embedding 让“理解”变成了“计算”,让语义变成了距离。
Embedding 的“长相”:向量、维度、归一化
1. 向量 (Vector)
Embedding 的输出是一组浮点数序列,例如 。它不是人类可读的答案,而是系统用于相似度计算的底层底座。
2. 维度 (Dimension)
向量中数字的个数即为维度。常见的维度包括 768、1024、1536 或 3072。
-
• 维度代表了特征的丰富度:每一个维度都可以看作是一个“语义轴”。 -
• 注意:维度并非越高越好。过高的维度会显著增加存储成本和检索延迟,甚至可能引入噪音。
3. 归一化 (Normalization)
常见的做法是将向量长度缩放到 1(即 范数归一化)。归一化后的向量在计算时,系统将不再关注向量的“绝对长度”,而只关注其在空间中的指向方向。这对余弦相似度计算至关重要。
相似度三剑客:Cosine、Dot Product、L2 到底怎么选
在工程实践中,你会遇到三种主要的度量方式:
-
• 欧氏距离 (L2 Distance):衡量两点间的直线距离。数值越小,内容越接近。 -
• 余弦相似度 (Cosine Similarity):衡量两个向量的夹角。夹角越小,相似度越高。它对长度不敏感,只关注方向,是目前最通用的方案。 -
• 点积 (Dot Product):同时受方向和长度影响。注意:如果向量已经过归一化,点积在数学上等同于余弦相似度。 许多高性能检索模型在训练时使用点积。
关键原则:相似度算法必须与模型训练时的目标函数保持一致。如果模型基于 Cosine 训练,而你在线上使用 L2 检索,效果会大幅下降。
语义的多维性:“相似”到底指什么
语义空间不是单一的。根据训练目标的不同,Embedding 的“偏好”也不同:
-
• 主题相似:如“猫的品种”与“猫的寿命”。 -
• 意图相似:如“如何退货”与“退款流程”。 -
• 事实相似:如“苹果公司总部”与“Apple HQ”。
在 RAG(检索增强生成) 场景下,我们通常更追求事实/答案相关性。因此,Embedding 空间不是天然形成的,而是被训练数据和目标函数塑形而成的。
新手直觉辅助:想象一个“语义星系”
虽然我们无法想象 1024 维的空间,但可以通过 t-SNE 或 UMAP 等降维工具将其投影到二维平面。你会看到:
-
• 所有关于“宠物”的文本聚集成一个“星团”。 -
• 所有关于“金融”的文本聚集成另一个“星团”。
语义星系的特征是:同类内容聚集,异类内容疏离。这种结构是语义搜索能够成立的物理基础。
新手误区:你很可能踩的三类坑
-
• 误区 1:把 Embedding 当成存储事实的“知识库”
Embedding 只是一张地图索引。真正的知识必须存储在原始文本或数据库中。向量库只是帮你找到了那张地图上的坐标。 -
• 误区 2:盲目追求高维度
1536 维的模型未必比 768 维的模型更适合你的业务。维度的增加会带来维度灾难,导致检索效率呈指数级下降。应通过 Benchmark(基准测试) 选择最适合的维度。 -
• 误区 3:忽视切片(Chunking)策略
Embedding 的效果极大程度上取决于你如何“切分”文档。如果一段文本太长,其语义会变得稀释且模糊,导致向量漂移,从而检索不到准确内容。
新手常见做法是“看到高维就觉得更强”,最后发现成本爆了、效果没提升。正确做法永远是:用评测决定维度与模型,而不是用直觉。
如果觉得内容不错,欢迎你点一下「在看」,或是将文章分享给其他有需要的人^^
相关好文推荐:
一个使用 OpenRouter 的 1 万亿令牌实证研究 | OpenRouter AI
D4RT:教会 AI 以四个维度看世界 | DeepMind
一个月内把编码主力交给 Agent 的真实体验 | karpathy
用于线性注意力的 Gated DeltaNet | Sebastian Raschka
DeepSeek的多头潜在注意力(MLA) | Sebastian Raschka
嵌入模型检索面临严重限制 | DeepLearning.AI
理解用于评估大语言模型(LLM)的四种主要方法 | Sebastian Raschka
从 DeepSeek V3 到 Mistral 3 Large:现代大语言模型(LLM)架构设计概览(三)| Sebastian Raschka
从 DeepSeek V3 到 Mistral 3 Large:现代大语言模型(LLM)架构设计概览(二)| Sebastian Raschka
从 DeepSeek V3 到 Mistral 3 Large:现代大语言模型(LLM)架构设计概览(一)| Sebastian Raschka
递归语言模型(Recursive Language Models) | Alex Zhang
重新构想 LLM 记忆:将上下文作为训练数据,使模型能够在测试时学习 | Nvidia
引入嵌套学习(Nested Learning):一种用于持续学习的全新机器学习范式
0条留言